

Author: Ronan Lashermes, Hardware Security Research Engineer at Inria. Results from a joint work with Hery Andrianatrehina, Joseph Paturel, Simon Rokicki and Thomas Rubiano at Inria.
When designing a modern core, achieving peak performance often comes with hidden risks, the severity of which is often underplayed.
The Spectre vulnerability [1], a prominent security flaw discovered in 2018, showed that speculative execution comes with inherent risks that have yet to be properly addressed. This article delves into the intricacies of microarchitecture and explores how these advanced techniques can inadvertently open doors to significant security vulnerabilities. Join us as we unravel the complexities of Spectre, understand its implications, and examine possible innovative RISC-V solutions designed to mitigate such vulnerabilities.
Microarchitecture in an Out-of-Order Execution Core
In modern processor cores, one of the key techniques to achieve maximum performance is out-of-order execution. Unlike strict sequential execution (“in order”), this method allows instructions to be executed as soon as their operands are ready, regardless of their order of appearance in the code. The goal: keeping the execution units, responsible for computing the instructions’ result, as busy as possible. An execution unit that doesn’t compute a result is just wasting time.
The life of an instruction is thus a bit more complicated than in the classic case: as usual, an instruction must be fetched, and then its decoding reserves the necessary resources for its execution. Once ready, the instructions are sent in order to the Instruction Queue. This queue establishes the dependencies between instructions: “attention, instruction i needs a result from instruction j”.
The first instruction in the queue, by definition, has all its dependencies fulfilled; it can be sent to an execution unit. But other instructions may also be independent of the following instructions in the queue; they too can be transferred to an execution unit, changing the order of execution of the instructions!
But there’s a problem, let’s imagine as in the example on Figure 1, that a division (a long operation to execute) is overtaken by an addition. We wouldn’t want to realize too late that it was a division by zero, an erroneous operation: the result register of the addition would be modified when it shouldn’t have been. For proper exception handling, we must be able to roll back to a valid state (before the addition was performed). This valid state only progresses when all previous instructions have themselves been validated: this is called a “commit”. This is done in order.
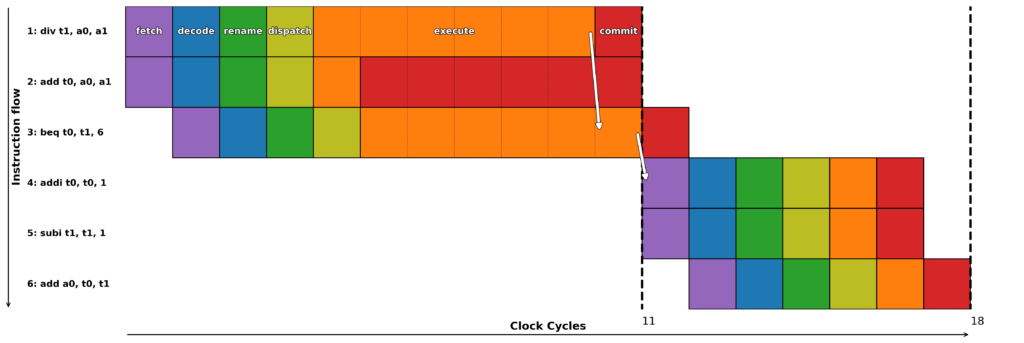
Figure 1: Out of Order
To ensure maximum utilization of processor resources, out-of-order execution is often not sufficient. Branches and other jumps are often the source of inefficiencies: we would need to wait for the resolution of the destination – “are the two operands equal for the beq (branch if equal)” – before fetching the next instructions. What a waste! We can do better. Since the processor can roll back to a previous valid state, we just need to make a guess. For example, we can guess that the branch will be taken and continue execution. If we guessed correctly, we saved precious execution time (cf Figure 2).
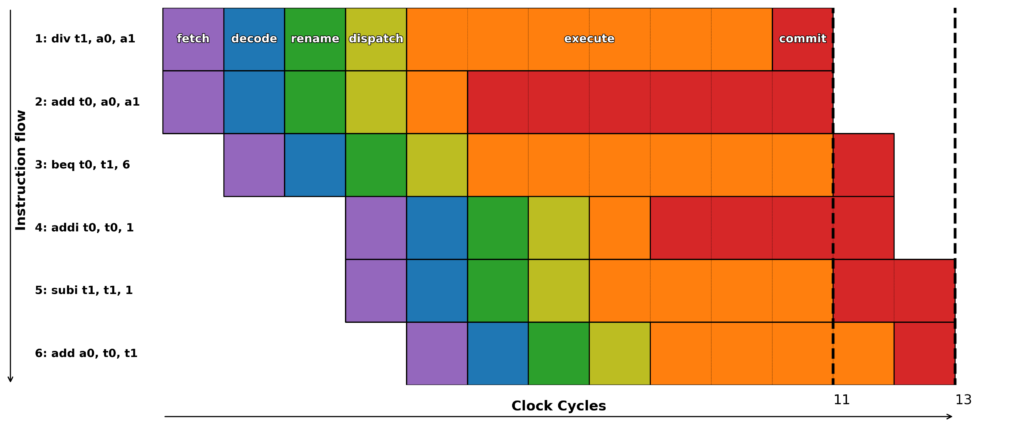
Figure 2: Good Prediction
But if unfortunately, we guessed wrong, no panic! When we finally validate the branch, we just need to cancel the incorrectly executed instructions and revert to that valid state (cf Figure 3). Fortunately, today’s branch predictors have success rates above 97%. This is known as speculative execution.
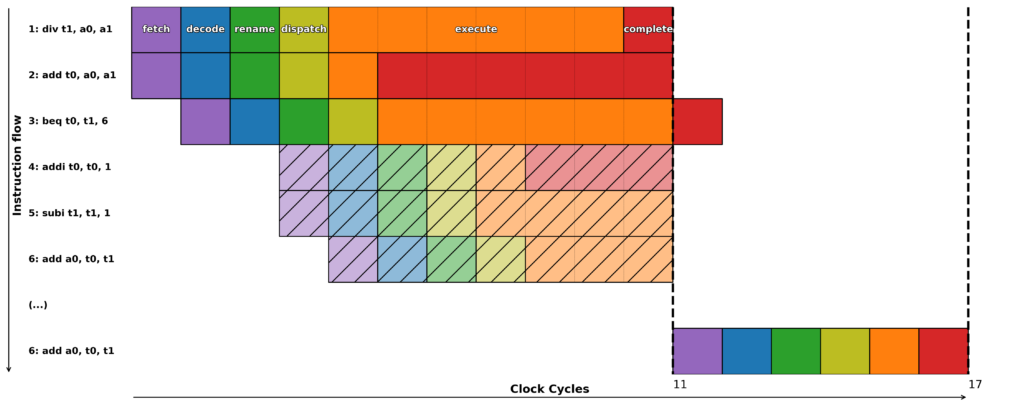
Figure 3: Bad Prediction
In a modern processor, instructions can be executed out of order when instructions are independents or because we guessed, without certainty, that it would be the next one to execute. This poses no problem since if we are wrong, it is possible to return to a previous valid state.
Unfortunately, this operating principle respected by modern high-performance cores is a source of security problems.
First Issue: Covert Channels
Covert channels are communication channels through which information can be transmitted stealthily, exploiting shared resources in unconventional ways. For example, a user process should not be able to send or receive information from another process on the same machine without the operating system’s approval or legally shared memory. Covert channels occur when the information is transmitted voluntarily by the target process, and side channels occur when the victim is an innocent process that does not intend to leak information.
These communication channels are typically prohibited through security interfaces: between processes (different ASIDs), between virtual machines (different VMIDs), and between privilege levels.
The problem is that processes share common microarchitectural resources: caches, branch predictors, etc. These resources can be used to construct covert or side channels. When a process reads data into memory, bringing it into the cache, another process can observe different access times due to this read. Similarly, the execution of a branch by one process modifies the branch prediction for all others, which is measurable.
In fact, any shared microarchitectural state can serve as a medium for a communication channel.
Second Issue: Transient Execution Attacks
In 2018, the Spectre attack was published, exploiting the speculative behavior of the core in a clever way. The idea for the attacker is to target branch prediction to execute the code they desire.
Consider the following code:
if a0 < max_len {
uint_32 s = data[a0];
arr[s << 6]
}
The attacker will execute it repeatedly with the condition a0 < max_len, and everything works fine. However, at some point, they will choose a value for a0 such that a0 + &data points to the secret s. The if condition is not met, and architecturally (if the instruction set semantics are respected), nothing happens. However, the branch prediction unit will predict that the condition is met since it has been met multiple times in the past. Thus, the secret s is read in the microarchitecture, and then this secret is transmitted over a covert channel (cf Figure 4). Here, using a read dependent on the secret, which allows writing the secret as the address (the tag) of a cache line, but any covert channel will do. Once the branch condition is computed and the misprediction detected, the microarchitecture rolls back, except for the trace left by a new cache line with the secret as its address.
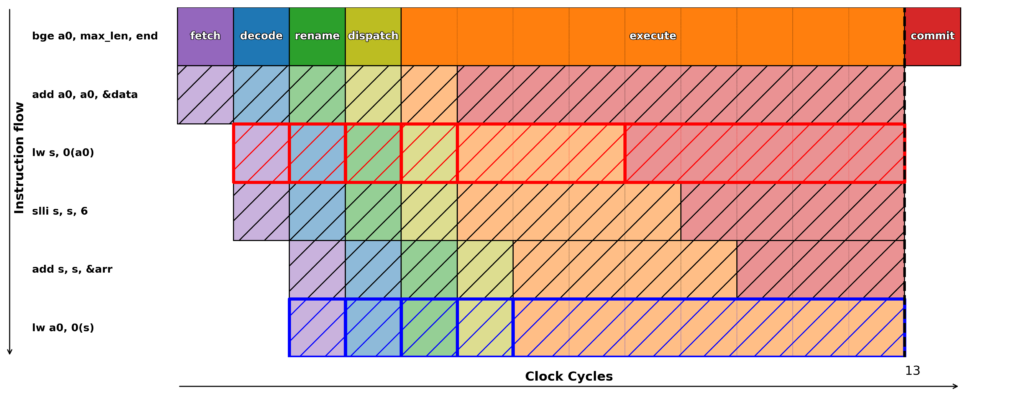
Figure 4: Spectre
If you have spent significant energy and budget to prove the good control flow properties of your application, tough luck! The microarchitectural control flow is arbitrary, it does not necessarily respect the architectural control flow defined by the instructions of your application. Thus, any load instruction can be used to read all memory if the MMU allows it.
For more details, see publication [2], which provides an overview of the state of the art of these attacks.
We find ourselves in an uncomfortable situation: any microarchitectural state can be used to construct a covert communication channel to communicate secrets, and the microarchitectural control flow is arbitrary, potentially influenced by the attacker.
Exploits are still difficult to implement, but the vulnerabilities are real. If your system requires strong, long-lasting security, I can only recommend not using an out-of-order execution core today.
RISC-V Solutions to Microarchitectural Vulnerabilities
The solutions are complex and may require modifications to the microarchitecture, the compiler, the operating system, and yes, even the instruction set.
Timing Fences Task Group
A primary approach is to limit covert channels, thereby preventing the exfiltration of secrets.
Preventing these channels is not easy and relies mainly on partitioning. Spatial partitioning involves physically separating microarchitectural states: for example, having a branch predictor for user-level and another for supervisor-level. It’s more difficult to apply when separating processes: we can’t have a predictor per process as there could be thousands! We would then prefer temporal partitioning, which simply means erasing all data (from the predictor, for instance) when necessary (e.g., during a process switch).
For more information, academic publications [3] and [4] address this issue.
Ensuring this partitioning efficiently is the goal of the Timing Fences Task Group of the RISC-V Foundation, which aims to introduce a new instruction, the timing fence, triggering this partitioning in the RISC-V instruction set.
Selective Speculation: An Exercise in Instruction Set Design
Unfortunately, we cannot rely solely on timing fences. They are very effective, but today they remain very difficult to implement perfectly in a complex microarchitecture. Moreover, they are only useful against a covert channel receiver that is itself a piece of code on the same core. These fences are useless against an attacker who physically measures execution times, for example, by detecting patterns in the power consumption trace.
There is another possible approach for countermeasures against Spectre: selective speculation. If speculative behavior is the problem, let’s stop speculating! However, we would still like to retain the performance benefits brought by speculation…
Therefore, we need mechanisms that allow not speculating in certain cases and speculating in others. There are at least two questions:
- What microarchitectural mechanisms, at what costs, what security, etc.?
- In which cases should we not speculate? This is the question of the security policy to apply.
These are the questions we are trying to answer in a work of the PEPR Arsene project, an academic project funded by the French government and bringing together several French research institutes: ANSSI, CEA, CNRS, IMT, Inria, and French universities.
New Instructions?
To stop speculation, it is sufficient to wait for the commit of the previous instruction before starting the execution of the next one. Thus, let’s define a new instruction fence.spec.all which has the semantics “the execution of fence.spec.all can only be completed when all previous instructions in the program order have been committed.” We implement our mechanisms in the open-source out-of-order processor NaxRiscv.
To prevent access to secrets, we want to forbid load instructions from addressing a secret in speculative mode. We thus place a fence.spec.all instruction before all load instructions. This is the security policy (load_before_all below in Figures 5 and 6). We implement our security policies in the open-source LLVM compiler.
For each mechanism and each security policy, we compile and execute the Embench benchmark suite. Is the execution time longer? Is the security better? And what does better security mean?
The execution time issue is quickly resolved: in our implementation, it takes almost 2.5 times longer to execute the benchmarks. For measuring security, we will save the pipeline state during the execution of the benchmarks. In these traces, we will count Spectre gadgets, defined as: in the same erroneous speculation window, we find a Spectre gadget if there is a load instruction whose data read is an argument of an instruction identified as leaking information (load, store, branch in our case). We thus measure the “accidental” presence of vulnerabilities. This measure has flaws, but if no Spectre gadget is found, we know that the attacker will have difficulties carrying out a Spectre attack. We thus obtain a quantitative measure of security: the sum of Spectre gadgets found in the benchmark suite.
In our case, we go from 545 gadgets found without speculation barriers to 0 with the barriers. This countermeasure is therefore effective from a security point of view but impractical: it’s better to use an in-order execution core, which will be more performant and just as secure!
We must therefore seek new possibilities for selective speculation. Let’s redefine our barrier as fence.spec rd, rs1 with new semantics: “fence.spec depends on the value rs1 and”touches”, while leaving it unchanged, the value of rd. The barrier can only complete its execution when the value of its source register is established in a non-speculative manner”. With the subtlety that if rd or rs1 are equal to x0, this designates a dependency with all registers.
This new instruction allows regaining some performance by allowing the core to reorder certain instructions that have no dependencies on the barrier.
Many other questions are raised: – Is a serializing instruction, which only works on the dependencies between instructions, more efficient, more secure? – Can we allow the reading of the secret with a speculative load, but not its use, by placing a barrier right after? – Are there possible compiler optimizations to minimize the number of barriers to place in a program? – Are there optimizations in the microarchitecture to minimize the performance cost of barriers?
A publication is underway, after which the source code (compiler, core, reproducible workflow) will be published.
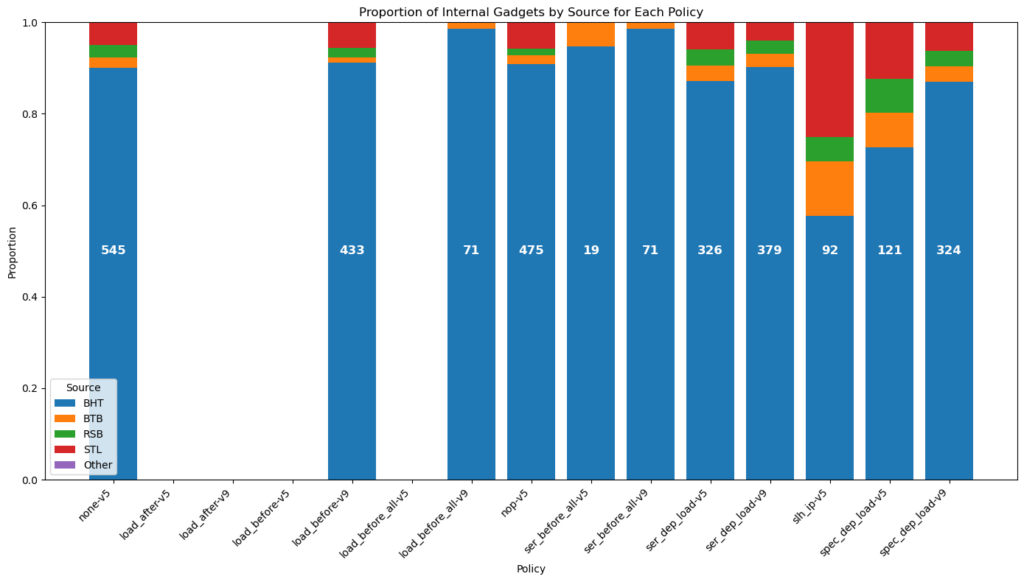
Figure 5: Gadgets proportions for various security policies
Figure 5 shows the sum count of Spectre gadgets found in the benchmarks traced by type of Speculation for each pair security policy x microarchitecture.
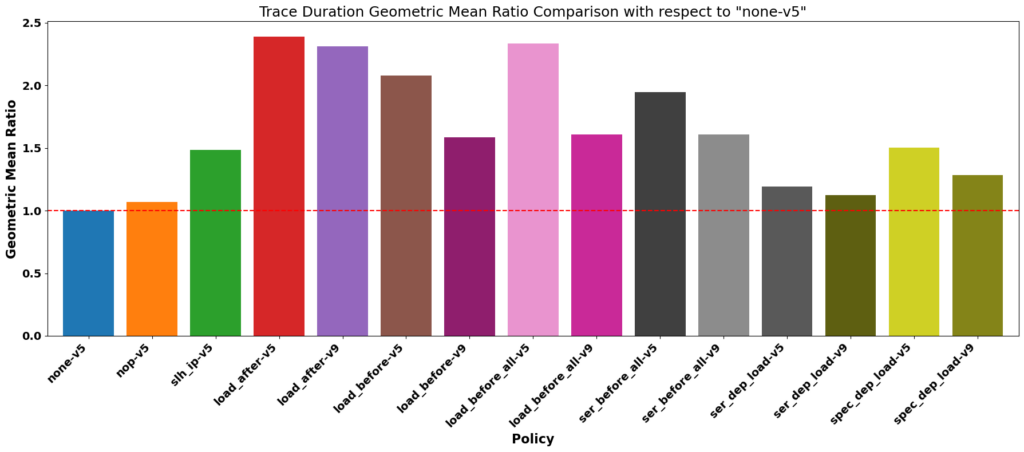
Figure 6: Benchmarks durations for various security policies
Figure 6 shows the benchmarks execution duration for each pair security policy x microarchitecture.
Conclusion
The open-source ecosystem around RISC-V is now mature enough to enable new open research that was impossible a few years ago. For this work, we can have one person adapting an out-of-order execution core (NaxRiscv) and another modifying a compiler (LLVM). They just need to agree on the encoding and semantics of new RISC-V instructions. By pointing to the git commits of our core and that of our compiler, an automated workflow allows compiling the Embench suite, synthesizing our core, creating a simulator using Verilator, executing (in simulation) the benchmarks, extracting execution traces, analyzing them, and generating performance and security figures.
Bibliography
[1] Spectre Attacks: Exploiting Speculative Execution by Paul Kocher, Jann Horn, Anders Fogh, Daniel Genkin, Daniel Gruss, Werner Haas, Mike Hamburg, Moritz Lipp, Stefan Mangard, Thomas Prescher, Michael Schwarz, Yuval Yarom
[2] This is How You Lose the Transient Execution War by Allison Randal
[3] Prevention of Microarchitectural Covert Channels on an Open-Source 64-bit RISC-V Core by Nils Wistoff, Moritz Schneider, Frank K. Gürkaynak, Luca Benini, Gernot Heiser
[4] Under the dome: preventing hardware timing information leakage by Mathieu Escouteloup, Ronan Lashermes, Jacques Fournier, Jean-Louis Lanet


