

Introduction
This has been a great summer! I was fortunate enough to be accepted into the Google Summer Code(GSOC) program for the “TensorCore Extension for Deep Learning” project offered by the Free & Open Source Silicon(FOSSi) foundation under the supervision of Theodore Omtzigt with Steven Hoover and Ákos Hadnagy. And I’ve been able to reach most of the milestones that we set out to achieve. Read on to understand what this project is all about and how you can contribute to it! The link to the GitHub repository has been included at the end of this post.
The Project
A. Background
In recent years, advances in Machine Learning (ML) and Deep Learning(DL) have been gaining substantial traction as these technologies become more and more capable of doing complex tasks. Deep Learning applications are continuing to grow — from Advanced Driver Assistance Systems(ADAS) in autonomous vehicles, to data centers and embedded applications like smart phones and drones — but so does the size of neural networks. The core operations in these Deep learning architectures are dot products(DP) and matrix multiplication (GEMM). Since these neural network applications have huge memory and compute demands, they require new kind of hardware architectures that can exploit this inherent Data Level Parallelism and high computational concurrency. As such, numerous hardware architectures have been proposed for running these networks such as GPUs, FPGAs and custom ASICs(with their own specific dataflows like TPU, Eyeriss). More recently though, Vector Processor architectures have seen a resurgence in mainstream ML and DL applications as they can exploit the data level parallelism in DL computations with a significantly lower instruction count and power consumption. This project focused on creating a Vector Coprocessor based on the RISCV vector extension that will connect to a Sequential RISC-V processor(e.g., WARP V). This tensor core processor will work as a deep learning accelerator.
B. Vector Processors Overview
To quote Hennessy Patterson[1]. —
“Vector architectures grab sets of data elements scattered about memory, place them into large, sequential register files, operate on data in those register files, and then disperse the results back into memory. A single instruction operates on vectors of data, which results in dozens of register–register operations on independent data elements.”
Both scalar and vector processors rely on instruction pipelining, but a vector processor operates on vectors of data (i.e., on 32 to 64 elements together), in a single instruction, thus reducing the number of instruction “fetch then decode” steps. Needless to say, this works best only if the applications have a inherent data level parallelism, which is the case in all deep learning applications. To see more examples and for a better understanding of vector architectures, please see references [2] & [3].
C. Project Goals
I set out with the following goals for this summer project-
- Research the architecture and micro-architecture details of vector processors and study currently available commercial and academic vector processors geared towards DL computations.
- Micro-architecture design and implementation of a simple open-source Tensor Core RISC-V vector processor to serve as a proof of concept — which can be used as a starting point for students to learn about the architecture and design of vector processors since most of the available designs are either commercially licensed or too complex for students at university level to understand and appreciate the advantages of vector processors.
- Create a test bench infrastructure for executing a suite of testcases(eg., SAXPY, dot product, etc.)on our implementation and validate the core design in simulation.
- To serve as a proof-point for a Deep Learning research platform to experiment with tensor operators (like fused dot products)and custom number systems(like Posits) . This design can be later used/modified to study tensor core based designs to accelerate Deep learning workloads at greater scale with custom instructions.
- To support the following instructions for majority of our deep learning workloads —
- Vector load
- Vector store
- Vector scale (VS operation)
- Vector add (VV or VS)
- Vector dot product (DOT)
Now, let’s delve into the architectural details of this design.
D. The Architecture
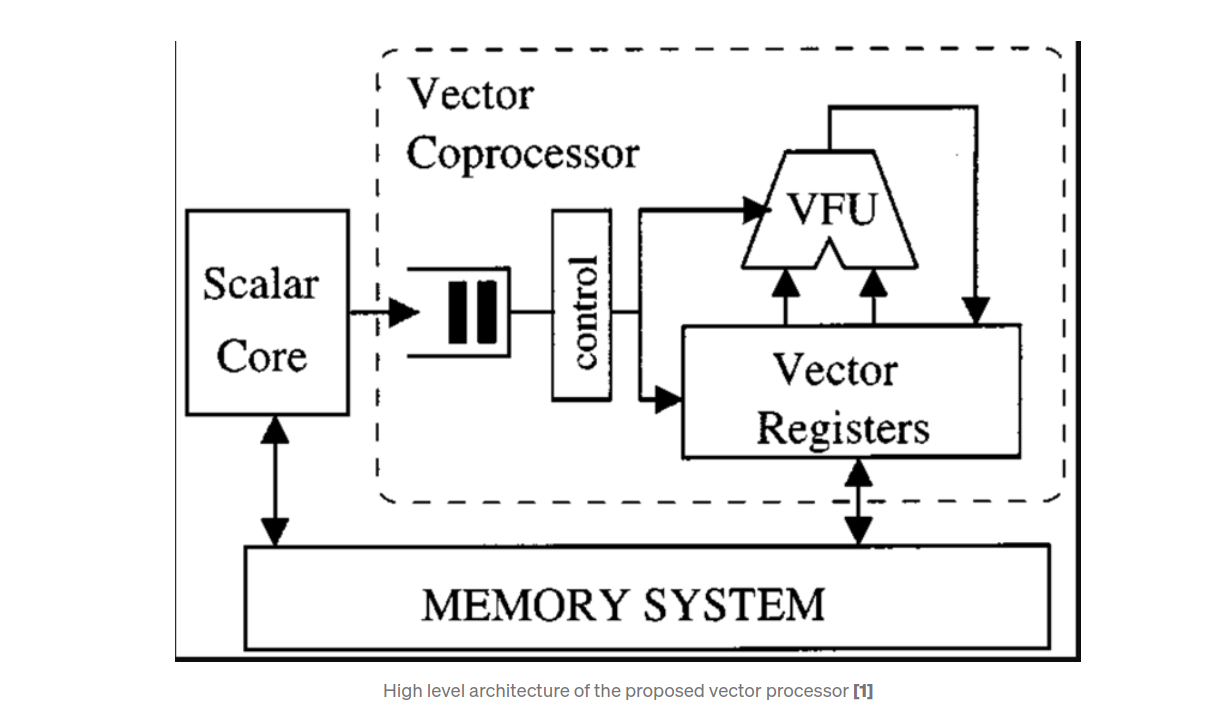
On a high level, the TensorCore processor has the following components —
- An instruction queue — that stores the vector instructions coming from the scalar core to decouple the instruction execution between the scalar and vector processor.
- Vector instruction decoder — to decode the different instruction types and flavors supported by the RISCV vector specification v0.10.
- A Sequencer(or control) — to transfer the incoming vector instructions to relevant functional units and control resource allocation.
- A vector register file(VRF) — comprising of 32 vector registers — implemented as an interleaved banked memory with a total of 4 banks. Each vector register consists of 32 elements each of which is 32 bit wide.
- A scalar register file — which can store the inputs of vector scalar(VS) operations(for eg., a SAXPY operation) and also the scalar output of reduction operations (for eg., a dot product).
- A single vector lane with a single Vector Functional Unit (VFU) — to perform required vector-vector and vector-scalar operations — (Add, multiply, dot product, etc.)
- An output queue — to store the results of the VFU; this would prevent banking conflicts on write-back path to the VRF when multiple VFUs output their results concurrently. This will be required when we scale up the design to run multiple instructions. In this implementation, this just serves as an implementation to support future work.
- An arbiter — to provide a fair access to various VFUs and output queues which are simultaneously trying to write back into VRF.
E. Implementation and Results
One of the objectives of this project was to demonstrate the power of Transaction Level Verilog (TLV) and Makerchip platform.
Transaction-Level Verilog (TL-Verilog) is an emerging extension to SystemVerilog that supports a transaction-level design by creating abstractions that match the mental models designers use to reason about their microarchitectures: pipelines, state, validity, hierarchy, and transactions . This results in code that is more robust, compact and less prone to bugs.
Makerchip supports “Visual Debug” (VIZ), a feature that enables custom visualization of circuit simulation, coded in JavaScript.
We can integrate designs coded in a mix of System Verilog and TLV or purely in TLV, from which the sandpiper compiler generates SystemVerilog (or Verilog) code in a variety of coding styles. Then we use verilator to compile the design code into a much faster & optimized model wrapped inside a C++ class which can run cycle-accurate simulations that are 100 times faster than interpreted Verilog simulators.
To do this demonstration, the decoder and instruction queue were implemented in TLV and the rest of the design was coded in System Verilog. This is a work that is currently under progress. As we don’t yet have the required C++ test infrastructure set up, we submit the final design as a System Verilog implementation with a simple SV test bench used for verifying the design by running a SAXPY loop example.
The SAXPY is one of the most common vector operations frequently encountered in linear algebra applications. Our SAXPY test is described as follows —
- Load a scalar value of ‘2’ into the scalar register file address location 0x2.
- Load vector register 0x1 with 32 elements in the following pattern — (4, 3, 2, 1, 4, 3, 2, 1……, 4, 3, 2, 1).
- Load vector register 0x2 with 32 elements in the following pattern — (-8, -6, -4, -2, -8, -6, -4, -2, ……, -8, -6, -4, -2).
- Compute the vector-scalar(VS) product between the scalar value in 0x2 of scalar RF with each element of vector register 0x1. Store the result back in vector register 0x1. Now the VR 0x1 has values (8, 6, 4, 2, 8, 6, 4, 2, ….).
- Compute vector addition (VV) between vector registers 0x1 and 0x2 and store the result back into vector register 0x3. Since the values are complements of each other, the output of this operation and final result stored in vector register 0x3 will be 0s for all 32 elements.
- Store this result from vector register 0x3 into memory using store operation. Since the memory interface is not a part of this project, the data is stored in a queue from which it can be transferred to a memory.
The design and test bench can be found in the /SV section of the Github repository. The incomplete /TLV section is also added into the repository. Users are free to come up with their own test cases.
Caveats —
- In the current implementation, the decoder, load and store unit are all implemented in the “sequencer module”. This decoder has decoding support for the basic operations needed by the TensorCore as described above. A more extensive decoder implementation can be found in the TLV directory.
- The current v0.10 of the RISCV Vector spec does not define the instruction encoding of a VV Integer dot product. For our goals, the VV Integer dot product is defined as follows —

The final output of this operation will be a scalar value which will be rounded back to 32 bits thus reducing the number of rounding steps. To implement this, we’ve defined our own custom encoding for this operation. The dot product instruction implementation is still under progress although the elementary operations required to compute the dot product are already supported.
The current design works on vectors with LMUL = 1 and elements with 32 bit precision only. The RISCV Vector extension supports elements with multiple bit precisions and multiple ways of grouping elements using different LMUL values. This will be the next goal for future work.
Since the design is still a work in progress, some additional control flow signals are included in the design to control the execution of operations explicitly from the test bench. These signals have been referred to as such in the comments wherever appropriate. Later, the sequencer and the decoder will communicate directly using internal signals without any explicit control through the test bench.
F. Future Work
Any work of such a huge scale always leaves tremendous scope for future work. Here is a list of features that I’ve planned for future work. You’re welcome to add new features as per your own specific requirements. This is the best part of working on an open source project!
- The current design is a single lane & single VFU implementation and hence can execute only 1 vector instruction at a time. To exploit the full potential of vector processors, we need to execute multiple instructions in parallel. This would require each lane to have multiple pipelined VFUs geared towards specific numerical operations(integer, floating point)and also multiple such lanes running together concurrently.
This will also highlight the importance of output queues , the arbiter and the reason for implementing the VRF as an interleaved banked memory. A good example of such work is in [5]. - Implement the dot product(DP) and the fused dot product (FDP) instruction with Reproducible Computation & Rounding Approach —
Reproducible computation requires control over rounding decisions. The fused dot product uses a quire to defer rounding till the end of the dot product. The cycle time of the quire needs to be balanced with the throughput of the multiply unit. The benefit of the quire is that the precision demands of the source number system are reduced. Research has shown that a 32-bit floating-point fused-dot product (FDP) can beat the precision of a 64-bit floating-point that uses fused-multiply-add (FMA). Similarly, we can use an 8-bit tapered floating-point, called a posit, to beat bfloat16. To reduce the complexity of the ALU design, we can limit the data types our vector machine supports to just a single data type, the standard posit. - Complete the TLV implementation of the design and test it using the sandpiper-verilator test infrastructure — to demonstrate the power of TLV to easily implement pipelined VFUs and create a design that is much less verbose and less prone to bugs.
Some of these projects will require considerable time and effort and I hope that other open source enthusiasts would participate in carrying this work forward in future GSOC editions!
Conclusion
Vector Processors were first proposed in the late ’80s and early ’90s but took a backseat due to the ever increasing performance offered by Moore’s law. With that coming to an end, and the continued growth of new AI applications, they’ve made a strong comeback and are at the forefront of current computer architecture research. Just over the past couple of years, many commercial vector processor designs have been presented which are customized to run deep learning and linear algebra computations. These include designs from Andes and SiFive, among others.
With the emergence and continuing evolution of the RISCV ISA, even the academics and open source enthusiasts now have the tools available to create their own custom designs. This TensorCore project is a small step in that direction. I hope it generates the required interest in the open source community towards creating custom designs and also serves as an introductory design to students and other enthusiasts who did not have any prior background on vector processors!
I also started out this project with absolutely no previous background on vector architectures and at the end of my journey, I’m much more aware, knowledgeable and excited to continue working on this new area of research. Indeed, it was a summer well spent!
GitHub Repo— TensorCore for Deep Learning
References
[1]. Kozyrakis, Christos & Judd, D. & Gebis, J. & Williams, Samuel & Patterson, David & Yelick, Katherine. (2001). Hardwater/compiler codevelopment for an media processor. Proceedings of the IEEE. 89. 1694–1709. 10.1109/5.964446.
[2]. Computer Architecture -A Quantitative Approach, Fifth Edition, John L. Hennessy, David A. Patterson — section 4.2 and Appendix G.
[3]. PhD Thesis “Vector Microprocessors” by Krste Asanović (berkeley.edu)