


The integration of AI algorithms on end devices (“Edge AI”, “AI of Things”, TinyML,..) is conquering the domain of resource constrained microcontrollers and cost-efficient ASIC designs. AI can improve the performance of basic sensors, helps to achieve light-weight object recognition and tracking in optical detectors and can be useful for HMI functions such as handwriting recognition. RISC-V makes it possible to quickly develop new hardware architectures to support these applications even in low-profile and low-cost systems – mainly due to its flexibility and free availability. I would like to talk about an example from my everyday work.
We work on integrated sensors for medical wearables and implants and are often equipping the RISC-V cores used in these projects with hardware support for Edge AI. In a typical application like cardiac rhythm detection, we only require a comparatively tiny neural network (ANN) paired with traditional signal processing. We still need to add some little bits of dedicated hardware to make the ANN inference fit for real-time execution. For these extensions we typically implement parts of the RISC-V SIMD [1] or vector specification [2], supplemented by some instructions for the computation of activation functions.
Lately, however, we are also starting to train these neural networks in-situ, e.g. to compensate for the physiological variation between patients. We can also use training of the ANNs during operation to detect and mitigate aging effects and malfunction. For the ANN training to work within sensible timing constraints, we equip our RISC-V cores with appropriate training accelerators. These result in a significantly larger chip area and thus higher costs and more importantly: higher energy consumption.
Not all accelerated functions are needed all the time, though. In particular the (in-situ-)training of the neural network, the pre-processing of sensor data with classical digital filters and periods for communication regularly alternate. It is an obvious step to switch off (power-gate) the hardware that is not needed in order to save energy – but this does not solve the problem of wasted chip area.
Get more out of small devices – dynamic reconfiguration
On FPGA platforms, the possibility of dynamic reconfiguration has been explored for such scenarios already for some time. Dynamic reconfiguration involves swapping out individual parts of an FPGA design at runtime, e.g. exchanging an AI training accelerator for a DSP coprocessor. Thanks to the availability of extension interfaces such as the XIF [3] and the flexibility of the instruction set architecture (ISA) in terms of user-defined opcodes and control and status registers (CSR) it is easy to hook-up a RISC-V softcore to a reconfigurable partition at the processor pipeline level, without going a long way across a system bus like AXI.
In our example (analysis of electrocardiogram data for heart rhythm observation), we have a simple RV32IMC core (AIRISC [4]) optimized for our Edge AI software library (AIfES [5]) on a Xilinx Virtex7 FPGA, which is extended via an XIF interface with hardware accelerated operations: a matrix multiplier and a subset of the SIMD commands. The accelerators are located in the dynamically reconfigurable part of the FPGA. Various partial bitstreams are stored in compressed form in the attached flash memory which also holds the bitstream for the static part. The AIRISC core reads a set of input measurements, applies some pre-filtering using optimized SIMD functions, and then searches for a specific disease pattern by feeding the data to an ANN.
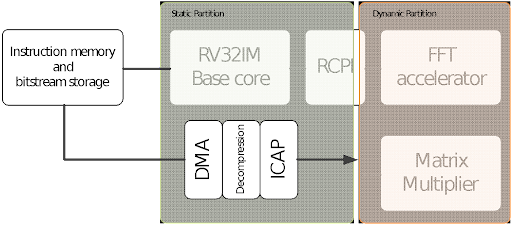
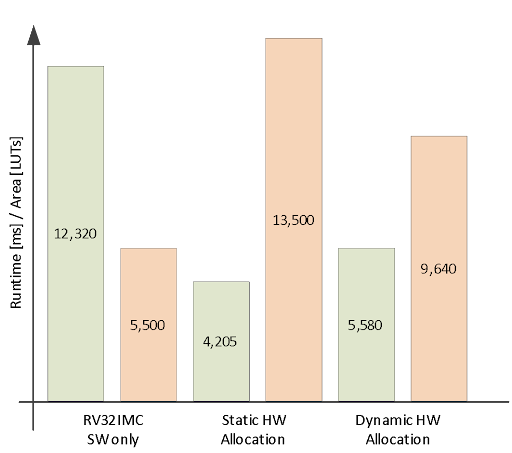
After reading the input data, we load the SMID extension into the reconfigurable domain and run the filtering. We then swap it for the matrix multiplier and run the inference of our AI model on the filtered data. For comparison, we tested a design without hardware support for filtering and AI, and a variant in which both accelerators are connected simultaneously.
The exchange of the partitions creates some overhead due to the time required to read and transfer the partial bitstream from the flash to the FPGA. But we can use a much smaller and lower power FPGA without losing significant speed. We pay with some additional non-volatile memory space, but this calculation often works out.
Best of both worlds – combining RISC-V and eFPGA
In an ASIC, we typically didn’t have the option for reconfiguration during runtime. Thanks to projects like openFPGA, we are now able to integrate our own application-specific FPGA fabric into chip designs and scale it precisely to the requirements of the function accelerators we need to support.
It is not trivial to determine the optimal allocation of the eFPGA resources at any given time. Is it more efficient to speed up a complex trigonometry function, or does an additional vector unit help us more? These questions can be answered by performing in-depth profiling in simulation or on a prototype. But especially when the system has to react to external events – e.g., user input or communication requests from other components – timing of the processes in the application may no longer be so deterministic. How nice it would be to automate reconfiguration?
Luckily, many free real time operating systems (RTOS) are available for the RISC-V architecture (like Zephyr [6] or FreeRTOS [7]), that can be given the task of scheduling the dynamic partitions. We extended the register set of the AIRISC core by some additional CSR registers which capture the number of calls of a specific computational expensive code subroutine. The user can load the function addresses into the registers and with each call of the function (jump-and-link to the stored address) a counter is incremented. We equip the scheduler of an RTOS (in our case FreeRTOS) with a mechanism that regularly determines the most frequently used function and checks whether hardware support is already loaded for it. If not, the scheduler loads an accelerator into the eFPGA and swaps out an unused one to make room first.
Each performance critical functions now consist of a header and an emulation function. The header part checks whether a suitable accelerator is loaded in the eFPGA and executes a corresponding custom instruction if this is the case. Otherwise the function branches into an emulation path and the calculation is done using only the RV32IMC instructions.
The process is shown in table 2 for a typical program flow. After the device switches from training the neural network to processing the input data, it takes some time to load the appropriate accelerator, but overall the execution time is significantly reduced. Despite the area and power overhead for the eFPGA, we can save chip area and therefore offer a less expensive product, reduce static power consumption, and relieve the programmer of the tedious profiling tasks.
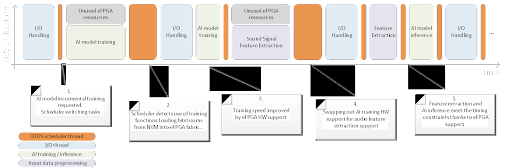
Figure 2: Automatic runtime optimization by dynamic reconfiguration
If you want to learn more about AI on small-scale RISC-V devices or dynamic reconfiguration, please contact me [8]. If you want to check out the AIRISC [4] core, our embedded AI optimized RISC-V implementation, you can get it under a permissive (solderpad) license from Fraunhofer IMS [4]. This allows you to evaluate AIRISC [4] and include it in your commercial designs free of charge. Functional safety (ISO26262) certified versions of AIRISC and documentation, as well as specialized embedded AI accelerators for various applications are provided as paid extensions. Our embedded AI software framework AIfES [5] is available under GPL for non-commercial use.

