


Author: Qiu Jing
The rise of AI has increased the demand for computing power by orders of magnitude. To meet the needs of AI for matrix computing power, processors of different architectures provide dedicated instruction set architectures for matrix multiplication acceleration. Examples are Arm’s Scalable Matrix Extension (SME)[1], x86’s Advanced Matrix Extensions (AMX)[2], and Power’s Matrix-Multiply Assist (MMA)[3]. Similarly, XuanTie series processors suggests a new structure, Matrix Multiply Extension (MME), based on RISC-V to meet the needs for AI computing power in various scenarios.
Relationship between XuanTie MME and vector extensions
We incorporate the design idea and implement of vector extension in the design process of XuanTie MME. We propose a new independent instruction set that allows decoupling from vector extensions.
XuanTie MME adopts an independent matrix extension implementation given the following four benefits:
- Independent programming models are suitable for various market needs. RISC-V adoption spans industries and workloads, not only to meet the needs of clouds and data centers, but also to apply to the consumer and IoT device markets. There is no fixed proportional relationship between vector and matrix computing power. An independent matrix extension facilitates access to different markets for RISC-V architectures.
- An independent matrix extension is designed to be developer-friendly. Developers spend minimal effort to coordinate the reuse of registers. They do not need to master two extensions at the same time to start network optimization, thereby reducing the development threshold and difficulty.
- A completely separated structure is more conducive to circuit implementation for hardware. This helps simplify the timing or layout optimization process.
- An independent programming model will assist implement thermal design for chips. Both vector and matrix extension operations consume a large amount of power. An independent matrix extension can separate heat generated by vector operations from that of matrix operations, thus reducing the difficulty in thermal design.
Independent matrix extensions may cause the following problems, and developers of XuanTie MME strives to reduce the impact of these problems during the process.
- The design of matrix and vector extensions are tightly coupled can reduce the overhead of hardware resources. In order to maximize resources, developers ensure the exact match between the computing powers. This requirement poses restrictions on the use scenarios of RISC-V. Although the two extensions are completely independent resources can be reused at the hardware implementation layer to reduce resource usage.
- An independent matrix extension can generate more data interaction for the processing units. XuanTie MME provides instructions to speed up requantification operations and reduce said interaction.
- Independent matrix register stacks result in more performance loss incurred from thread switching. XuanTie MME introduces Dirty Flags similar to vector extensions to save used registers only.
XuanTie MME uses a completely independent matrix processing unit without reusing vector registers. Data interaction between vector and matrix extensions is achieved through memory operations.
Programming model
XuanTie MME adds eight 2D matrix registers, as shown in the figure below.
MLEN indicates the length in bits for each register row. MLEN must be the nth power of 2, such as 128, 256, or even larger. Different MLENs generally mean different computing power. Each chip can choose a suitable MLEN size based on computing power requirements and hardware resources.
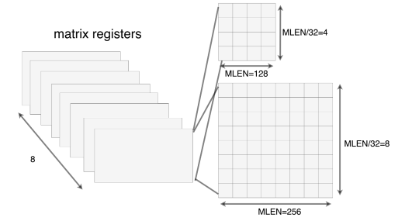
In XuanTie MME, the number of rows in a matrix register is calculated by using MLEN/32. When MLEN is 128, a matrix register can hold 4*4 32-bit data entries. When MLEN is 256, a matrix register can hold 8*8 32-bit data entries.
XuanTie MME supports operations on elements with different bit widths, such as int4, int8, fp16, bf16, fp32 and so on. For the same MLEN, when the element bit width is halved, the number of rows of the matrix remains unchanged, and the number of columns of the matrix is doubled. Taking MLEN=128 as an example, a matrix register can hold 4*2 64-bit data entries, 4*4 32-bit data entries, 4*8 16-bit data entries, 4*16 8-bit data entries, or 4*32 4-bit data entries. No matter how the element bit width changes, the number of rows is always guaranteed to remain unchanged, which helps software developers understand and use XuanTie MME.
Instruction set
Matrix multiply-accumulate instructions
XuanTie MME is designed to accelerate AI operations. Matrix multiply-accumulate operations are the key objects for MME. MME provides two types of instructions: integer multiply-accumulate operation mmaqa and floating-point multiply-accumulate operation fmmacc. The following figure shows how multiply-accumulate instructions work. Matrix A is multiplied by Matrix B and then accumulates Matrix C. The calculation result is then stored back in Matrix C. The source and destination operands in multiply-accumulate operations only use matrix registers, and no additional accumulation registers are introduced. This unified matrix register, rather than separated accumulation, simplifies toolchain design.
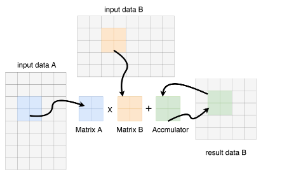
The fmmacc instructions implements floating-point matrix multiplication. The bit width of the source operand is the same as that of the destination operand. Element bit widths are included in the instruction code, and support half precision (fmmacc.h and fmmacc.b) and single precision (fmmacc.s). We can choose whether hardware is to support an element bit width as needed.
Mmaqa is designed for integer matrix multiplication instructions. The bit width of the source operand is included in the instruction code and supports int8 (mmaqa.b) and int16 (mmaqa.h). The source operand supports both signed and unsigned numbers. The accumulation operand is a signed number by default. The multiplication result is extended by the sign bit and then used for accumulation. If the addition overflows, the low bit is retained without saturation processing. For a mmaqa instruction, the bit width of the destination operand is 4 times that of the source operand, that is, the bit width of the accumulation operand in a mmaqa.b instruction is 32 bits, and the bit width of the accumulation operand in a mmaqa.h instruction is 64 bits. pmmaqa.b indicates pair instructions. In a pair instruction, an 8-bit data entry is considered as a pair of 4-bit data entries, so as to support the 4-bit matrix multiplication operation. The bit width of the accumulation operand in a pmmaqa.b instruction is 32 bits. Hardware can be chosen to support one or more data types as needed.
Matrix store/load instructions
XuanTie MME provides matrix load/store to reduce memory bandwidth. Matrix memory access can load/ store one 2D matrix simultaneously. For example, the matrix load instruction will import multiple rows of contiguous bytes/halfwords/words/doublewords to matrix registers. The first source register serves as the base address. The second source register acts as a stride value. XuanTie MME also provides stream load/store, which gives a hint to the implementation that the data will be likely not reused in the near future. The matrix register load/store is provided to speed up context switching.
Other instructions
XuanTie MME also supports matrix computations to accelerate quantification and requantification operations. A total of more than 20 instructions have been added to MME to improve AI computing power.
XuanTie MME supports the following features for AI applications. Firstly, MME is scalable. The MLEN can be expanded from 128 to 1,024 or even larger, and the corresponding peak computing power can also be expanded from 0.5 TOPS to 32 TOPS. Secondly, MME can guarantee the portability of binary code. When you change the MLEN, you can run the binary code with no need for rewriting or recompiling. Thirdly, XuanTie MME decouples matrix extensions from vector extensions, giving greater flexibilities for specific chip designs. MME supports various common AI application data types, which allows toolchain development user-friendly and helps reserve sufficient room for subsequent matrix extensions.
Our design scheme has been open sourced on GitHub. Should you need more information or send feedback, please contact us at https://github.com/T-head-Semi/riscv-matrix-extension-spec.
- Intel®Architecture Instruction Set Extensions and Future Features Programming Reference
- Arm® Architecture Reference Manual Supplement, The Scalable Matrix Extension (SME), for Armv9-A
- A matrix math facility for Power ISA™ processors

