


Introduction to Triton
Triton is an open-source, Python-based Domain-Specific Language (DSL) developed by OpenAI to simplify the writing of high-performance GPGPU code. It was first introduced in 2019 by Tillett et al. in a paper titled “Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations” at Harvard University. The core design concepts of Triton include block-level parallel programming, LLVM-based intermediate representation, and multi-level optimization processes. Since 2020, OpenAI has taken over the development of Triton, releasing version 3.0 after years of iterations. Several open-source projects, including PyTorch, Unsloth, and FlagGems, have adopted Triton to develop part or all of their kernels.
Initially, Triton only supported NVIDIA consumer-grade GPUs, but it gradually expanded to industrial-grade GPUs like A100 and H100. Other AI chip vendors, including both domestic and international GPGPU and DSA accelerator hardware platforms, have also begun supporting Triton. At Triton Conference [1][2] 2024 in Silicon Valley in September, chip manufacturers like Intel, AMD, Qualcomm, Nvidia, together with solution providers like Microsoft and AWS shared their progress and performance results with Triton, showcasing its broad application across various hardware platforms. Furthermore, Triton has also begun exploring CPU adaptation to further enhance hardware compatibility.
At the hardware level, Triton targets Cooperative Thread Arrays (CTA), while at the software level, it focuses on block-level parallel programming. Compared to higher-level frameworks like PyTorch, Triton is more focused on the detailed implementation of computational operations. Developers can enjoy more freedom in manipulating tile-level data read/write operations, execute computational primitives, and define thread block partitioning methods. Triton hides the scheduling details at and below thread block level, with the compiler automatically managing shared memory, thread parallelism, memory coalescing and tensor layout, thereby reducing the difficulty of parallel programming and improving development efficiency. Developers only need to understand basic parallel principles and focus on algorithms and their implementations, which in turn help to write high-performance kernels efficiently.
Although Triton compromises some programming flexibility, it still achieves comparable performance to CUDA through multi-level compilation and optimization. For example, in the official tutorial, the Triton implementation of matrix multiplication achieves performance on par with cuBLAS under specific testing conditions, fully utilizing the hardware’s computational capacity and showcasing outstanding performance [3].
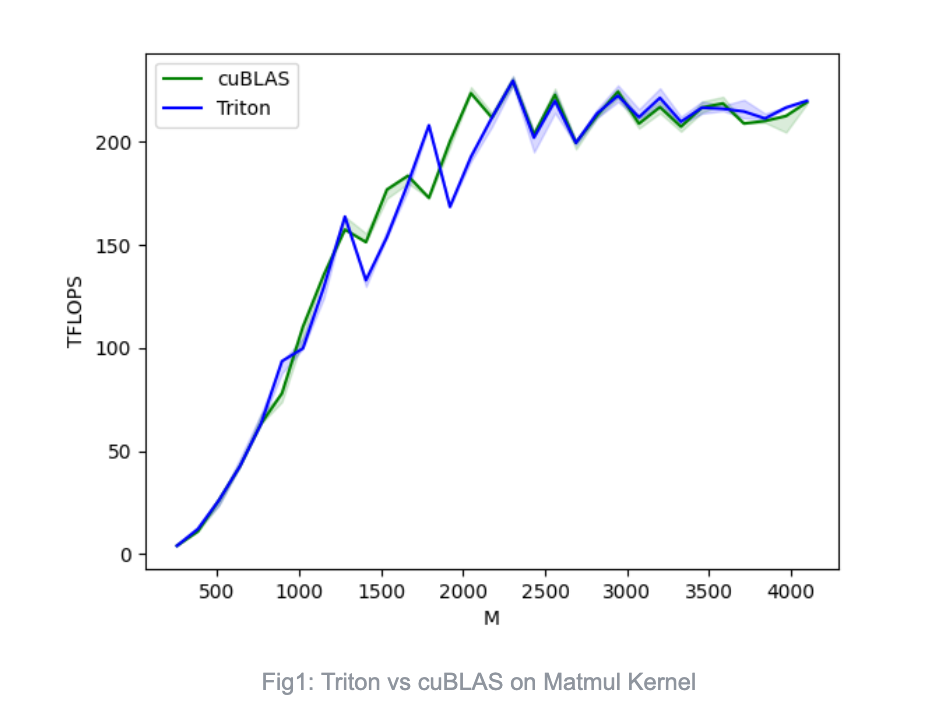
Triton on CPU
Background
There are several Triton for CPU projects including the official Triton-CPU [5] from OpenAI and Microsoft’s Triton-Shared [7], along with other efforts such as Cambricon’s Triton-Linalg[8]. However, Triton-Linalg has only completed Triton language frontend integration, with backend CPU support still under development. Triton-Shared integrates MLIR’s linalg dialect into its Triton’s Intermediate Representation (IR) before lowering it to LLVM IR dialect. This pipeline lacks target dependent optimizations and remains experimental with issues on performance. Triton-Shared is primarily used to explore the possibility of expanding Triton support on CPU platform.
In contrast, Triton-CPU integrates MLIR’s vector dialect into Triton’s high-level IR to effectively vectorize the code. Additionally, multithreading is supported with auto generated OpenMP C code from a Python script, leading to a significant boost in parallel computation performance on CPU. In Triton community meetup[4] in August 2024, Triton-CPU demonstrated performance that was comparable to or even better than Torch on CPU, highlighting its potential in efficiently utilizing multi-core resources and instruction-level parallelism.
RISC-V, an open Instruction Set Architecture (ISA), has shown immense potential in the AI chip domain. Its flexibility, scalability, and support for customization make it an ideal choice for designing efficient AI processors. The scalable vector extension instruction set (RVV) has shown powerful vector processing capabilities, enabling efficient execution of parallel computing tasks, which is a key requirement for AI algorithms such as matrix multiplication and vector operations. Additionally, RISC-V allows developers to add custom instructions to accelerate specific AI computational tasks. For instance, specialized instructions can be designed for common neural network operations like convolution and activation functions to improve execution efficiency.
The Python language features of Triton and its higher-level programming model abstractions can significantly reduce the costs for chip manufacturers in developing and maintaining kernel libraries. Leveraging the multi-level intermediate representation (IR) mechanism provided by the MLIR software stack further enhances the adaptability of Triton’s kernel libraries to the RISC-V architecture, improving compatibility among different RISC-V AI chips. Additionally, the highly customizable nature of RISC-V AI chips allows manufacturers to design specialized instructions tailored to specific kernels, thereby fully unleashing the potential of the kernel libraries. Therefore, in-depth research on Triton kernel performance on existing RISC-V AI chips, and optimizing for major performance bottlenecks, is critical for advancing the development of Triton, MLIR, and the RISC-V ecosystem. This not only promotes the collaborative development of various RISC-V AI chips but also contributes to the prosperous development of the entire ecosystem.
Goals
The Triton-CPU Meetup only showcased the performance of some kernels on the x86 platform, while the performance of Triton kernels on the RISC-V platform has yet to be fully explored. This study seeks to compare the performance of kernels written in OpenAI’s Triton language and C language with the same algorithm, focusing solely on the impact of compiler optimizations. By deeply analyzing the differences in the assembly codes, this research aims to identify further optimization opportunities for the Triton-CPU compiler, providing guidance for subsequent performance improvements.
Development Environment
We use RISC-V cross compilers on x86 platform to generate RISC-V executables. Specifically, we generate LLVM IR using Triton-CPU, then cross-compile it into assembly code for RISC-V target. The final RISC-V binary runs on SpacemiT’s K1 development board, which includes 8 dual-issue RISC-V CPUs with 256bit RVV 1.0 support. This setup is ideal for testing kernels’ performance with the hardware’s parallel computing capabilities.
For the compiler, the C code was compiled using RISC-V GCC 15.0.0 and our ZCC 3.2.4 (an in-house optimized LLVM-based compiler). The LLVM IR for Triton kernels was generated using the Triton-CPU project’s built-in compiler and then compiled into RISC-V assembly code using ZCC. The compilation was consistently done with -O3 optimization level to ensure maximum performance.
Kernel Implementation
We selected commonly used kernels in large language models, such as rope, matmul, softmax, layernorm, as well as image processing kernels like resize, warp, and correlation, for benchmarking. The kernel implementation can be found in Terapines’s AI-Benchmark repository [9].
The implementation of these kernels uses standard algorithm. Although not every kernel is tuned to it’s best algorithm implementation, efforts were made to ensure consistency between the C language and Triton language implementations. The vectorization and multithreading in the C language are primarily achieved through #pragma directives, without using any RISC-V intrinsics, relying entirely on the compiler’s automatic optimization capabilities.
We strive to ensure a fair comparison of the compiler performances across different programming language implementations of the kernels in our design. This will also help us gain a solid baseline for subsequent optimizations.
Performance Analysis
(Due to space constraints, some kernels’ performance have been abridged. For the full article, please visit https://github.com/Terapines/AI-Benchmark/tree/main/doc.)
On the same hardware platform with the same -O3 optimization level, we tested the performance of both Triton and C kernels. For each kernel, the running time in single, four, and eight threads (T1, T4 and T8) was measured with different input shapes. To make comparison and presentation easier, the performance data for different input/output shapes were normalized relative to the kernel’s time complexity, with the final performance results displayed in GB/s (the higher the value, the better the performance).
Softmax
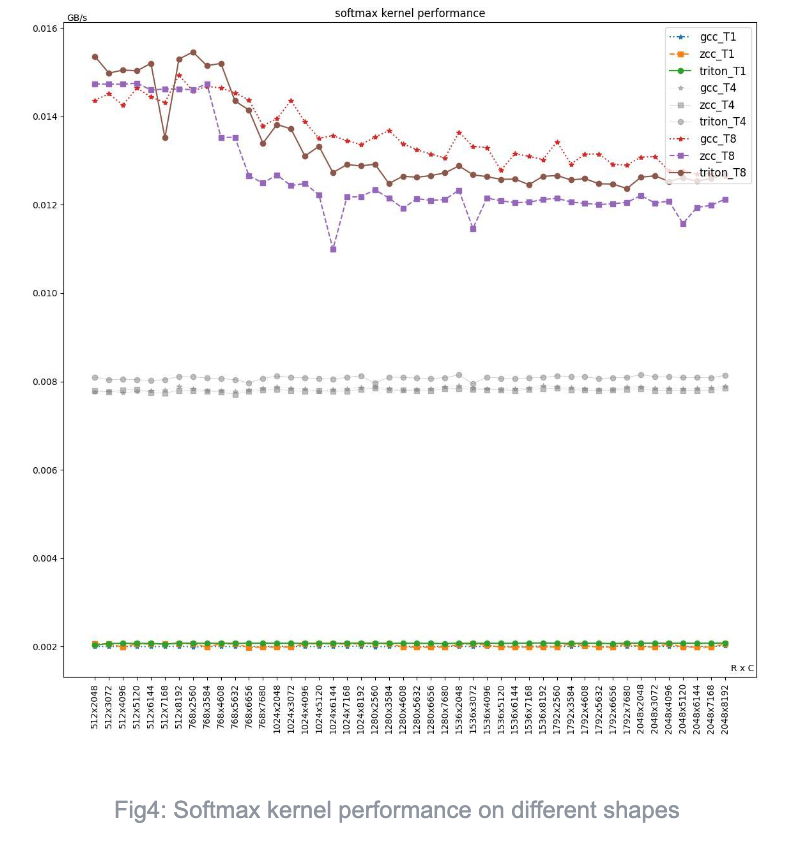
| Average performance on different compiler | |||||||
| Average (GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
| T1 | 0.00200 | 0.00202 | 0.00207 | 102.53% | 103.50% | ||
| T4 | 0.00783 | 0.00780 | 0.00808 | 103.59% | 103.17% | 100.00% | 100.00% |
| T8 | 0.01356 | 0.01267 | 0.01330 | 104.99% | 98.09% | 100.00% | 100.00% |
| T4/T1 | 378.27% | 376.71% | 390.25% | 103.59% | 103.17% | ||
| T8/T1 | 654.91% | 611.87% | 642.39% | 104.99% | 98.09% | ||
The performance of Triton, ZCC, and GCC are similar in softmax. Triton shows 2-4% higher performance than both GCC and ZCC in single and four threaded executions. However, in the case of eight-thread, GCC outperformed Triton by 2%. The primary reasons for performance difference may include:
- First step in Safe-Softmax kernel (max element calculation): Both Triton and GCC generate vfredsum (vector reduction). Triton uses m4 grouping, while GCC uses m1. ZCC generates an unroll of 8 scalar fmax operations instead generating vfredsum.

- Second step (denominator calculation, the sum of the exponents of all elements): Triton, GCC, and ZCC all generate scalar operations, with Triton unrolling core loops 8 times, while GCC and ZCC do not.

- Third step (Softmax calculation): Triton, GCC, and ZCC all use vfdiv.vf, Triton uses m4 grouping, GCC uses m1 grouping, and ZCC uses m8 grouping.

Resize
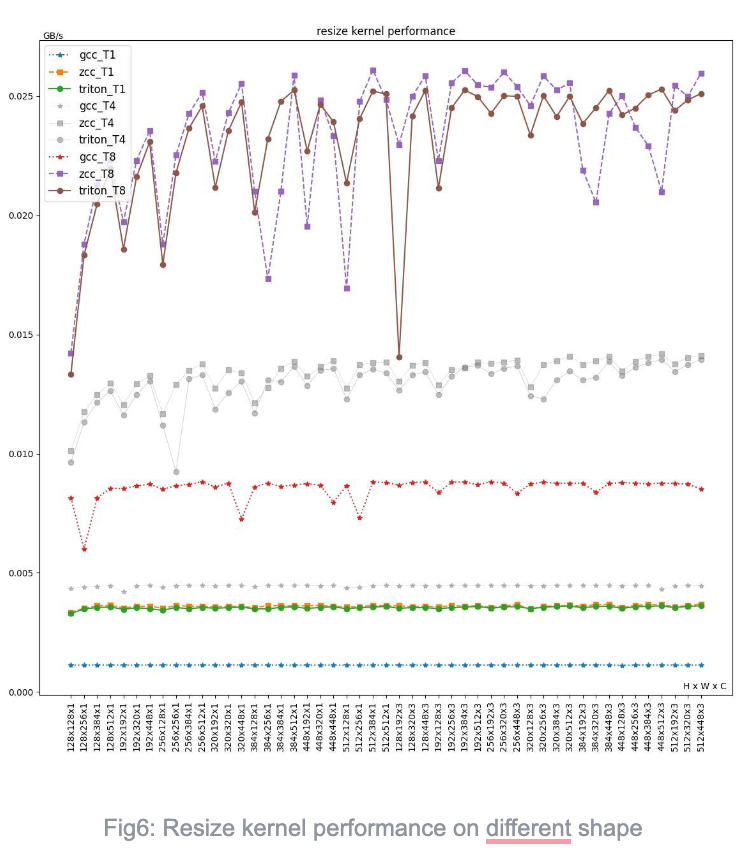
| Average performance on different compiler | |||||||
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
| T1 | 0.0011 | 0.0036 | 0.0035 | 98.43% | 314.69% | ||
| T4 | 0.0044 | 0.0134 | 0.0129 | 96.35% | 289.70% | 100.00% | 100.07% |
| T8 | 0.0086 | 0.0231 | 0.0231 | 100.35% | 269.72% | 100.01% | 100.11% |
| T4/T1 | 125.67% | 377.60% | 363.81% | 96.35% | 289.49% | ||
| T8/T1 | 242.47% | 650.97% | 653.24% | 100.35% | 269.42% | ||
Triton and ZCC show similar performance across all threads and input shapes, while GCC’s performance lags significantly. The primary reason for performance difference may include:
- GCC’s use of strided load for discrete memory accesses, resulting in many additional instructions. In contrast, ZCC and Triton use index load directly, resulting in fewer instructions generated compared to GCC, without producing permutation-type instructions (such as vslidedown).
For example, in the following C source code, the index x0 and x1 for src_ptr0 and src_ptr1 are variables with no fixed stride length, making them unsuitable for strided load. However, GCC still uses the strided load instruction vlse8.vv5,0(a3),zero (with a stride value of 0) and extracts each element from the vector register into scalar registers using vslidedown.vi and vmv.x.s for computation. This optimization approach, which results in a large number of unnecessary instructions, is essentially a deoptimization.
C++ // Resize kernel: input data load for (size_t w = 0; w < dst_width; w++) { uint16_t input_x = (uint16_t)w << (hw_fl - 1); uint16_t x0 = (input_x >> hw_fl); uint16_t x1 = std::min(x0 + (uint16_t)1, width - (uint16_t)1); int16_t y0x0 = src_ptr0[x0]; int16_t y0x1 = src_ptr0[x1]; int16_t y1x0 = src_ptr1[x0]; int16_t y1x1 = src_ptr1[x1]; // ... }

Triton-CPU Performance Issues
(Due to space constraints, Triton-CPU Performance Issues has been abridged. For the full article, please visit https://github.com/Terapines/AI-Benchmark/tree/main/doc.)
Summary
Despite facing performance issues on the RISC-V platform, such as register spill, fixed-length vector, discrete memory access vectorization, and the context storage overhead introduced by multithreading, testing results indicate that the performance of Triton-CPU on the RISC-V architecture can nearly reach that of traditional C kernel compilers through a series of experimental optimizations. This result not only validates Triton’s immense potential in the high-performance computing field but also highlights its broad application prospects in the open-source RISC-V architecture.
Looking ahead, as more and more optimization to be applied to Triton compiler, Triton is expected to further overcome current performance bottlenecks, thereby becoming the preferred kernel library programming language solution for RISC-V platform. Additionally, with the ongoing proliferation of the RISC-V architecture in the industry and the continuous expansion of application scenarios, the Triton kernel library, with its high usability and maintainability, as well as the compatibility and scalability brought by the MLIR (Multi-Level Intermediate Representation) compiler technology stack, will significantly enhance its competitiveness in the ecosystem.
Moreover, the synergistic development of related ecosystems, such as RISC-V, Triton, and MLIR, will promote the shared prosperity of open-source technology, further driving the deep integration of high-performance computing and open-source hardware architectures. Through this synergy, not only can technological innovation be accelerated, but a positive ecological cycle can also be formed, providing stronger support for future computing demands.
References
[1] Triton Conference @ Silicon Valley: Chip and AI Giants Gather (Triton 大会@硅谷:芯片、AI大厂齐站台) https://mp.weixin.qq.com/s/euX2nxQ4lhG6yaLYMugyrw
[2] Triton Conference 2024 https://www.youtube.com/@Triton-openai/videos
[3] Opening a New Era in Large Models: The Evolution and Impact of Triton (开启大模型时代新纪元:Triton 的演变与影响力) https://Triton.csdn.net/66f22b7759bcf8384a63a1c9.html
[4] August Triton Community Meetup https://www.youtube.com/watch?v=dfL3L4_3ujg&t=634s
[5] Triton-CPU Repository https://github.com/Triton-lang/Triton-cpu
[6] Triton’s documentation https://Triton-lang.org/main/python-api/Triton.language.html
[7] Triton-Shared Repository https://github.com/microsoft/Triton-shared
[8] Triton-Linalg Repository https://github.com/Cambricon/Triton-linalg
[9] AI-Benchmark Repository https://github.com/Terapines/AI-Benchmark
More detailed version of this article is available on our GitHub repository https://github.com/Terapines/AI-Benchmark

