



Tammo Mürmann has just commenced his PhD studies at the Technical University of Darmstadt as part of the Embedded Systems and Applications Group (ESA). During his studies, he already participated in the development of a high-level synthesis compiler (Longnail) that was recently presented at ASPLOS. Automated generation of custom RISC-V ISA extensions and tooling support continues to be the focus of his research.

Florian Meisel is a PhD candidate at Technical University of Darmstadt and part of the Embedded Systems and Applications Group (ESA). As part of his studies, he has worked on the design and integration of a security tracing interface into a range of RISC-V cores (RT-LIFE) and its application to software fuzzing (TaPaFuzz). His research activities continue to revolve around the integration and extension of RISC-V processor microarchitectures with SCAIE-V.

Andreas Koch leads the ESA Group at TU Darmstadt. He has worked in domain-specific computing for more than three decades now, initially focussing on FPGA-based accelerators, but recently shifting to RISC-V processors extended with custom instructions. He is PI in a wide range of research projects, including the German ZuSE-Scale4Edge and MANNHEIM-FlexKI endeavors, as well as the joint EU/German TRISTAN project, in which the results reported here were created.
Custom Instruction Set Architecture eXtensions (ISAX) are an energy-efficient and cost-effective way to accelerate modern workloads. However, implementing, integrating, and verifying an ISAX into an existing base core is a very time-consuming task that only a few can do. Experimenting with combinations of ISAXes and base cores often requires a complete redesign due to lacking portability across different microarchitectures.
To address these shortcomings, as part of the projects Scale4Edge and FlexKI, we have developed our own end-to-end flow that is the subject of this blog post.
CoreDSL
To make the description of ISAXes accessible to domain experts, we have created the open-source high-level language CoreDSL. Figure 1 shows an example of CoreDSL code to describe an ISAX computing the dot product between two packed vectors. CoreDSL combines familiar C-like syntax and constructs, such as the for-loop in Line 10, with the means to express arbitrary bit-widths (cf. Line 9), while having a strong type system that prevents unintentional loss of precision and sign information. Due to the latter, an explicit cast from the signed<32> to unsigned<32> is required in Line 15 for the assignment to X[rd] to be legal. CoreDSL has been designed from the ground up to concisely express ISAXes, including their encodings and architectural state, without having to deal with low-level details such as clock cycles and resource allocations. Hence, ISAX descriptions written in CoreDSL are naturally vendor-independent and can be used as a single source-of-truth across all steps of the tool flow (e.g., compiler, simulator, etc.).
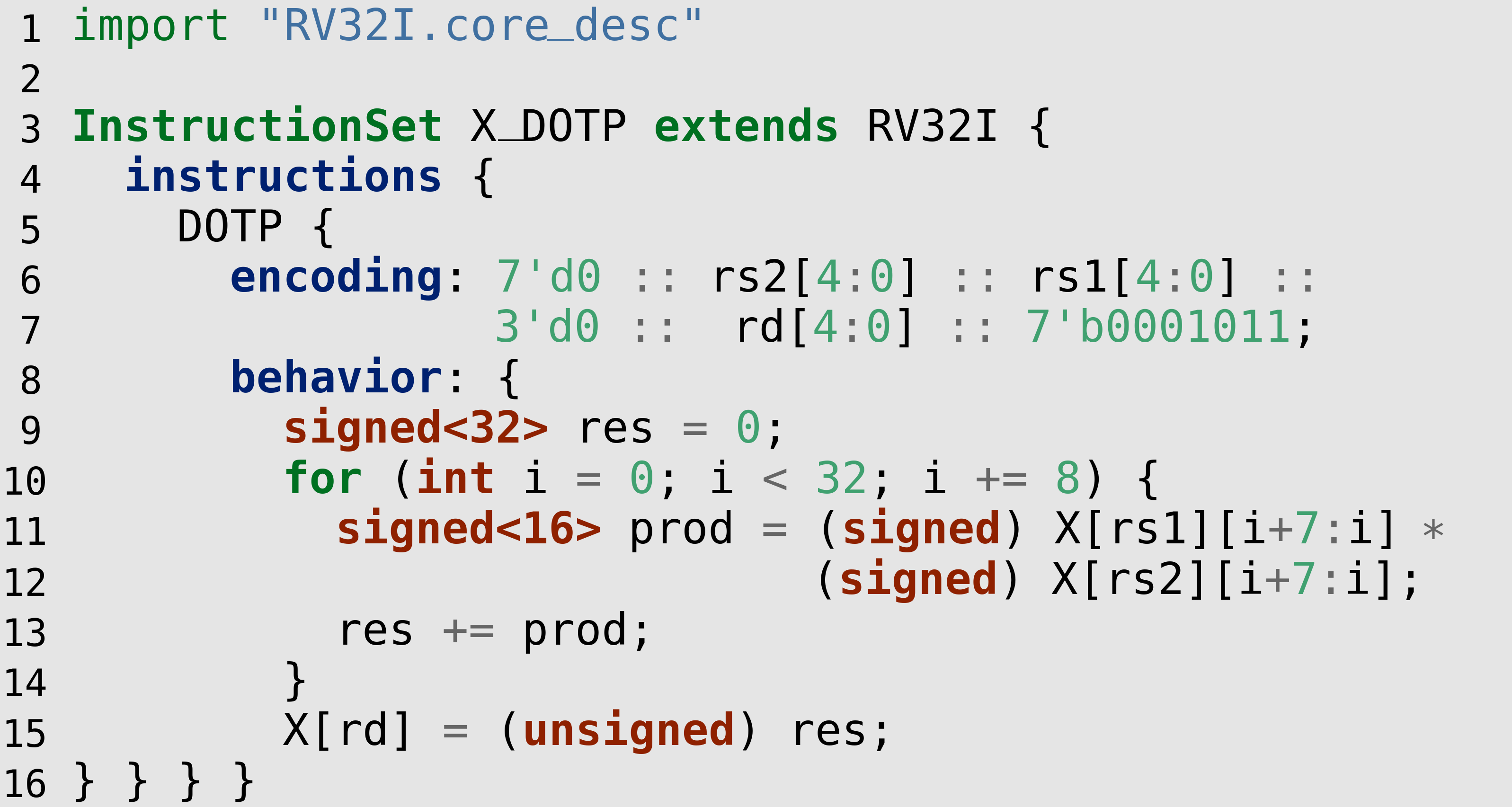
Figure 1: CoreDSL code snippet describing a packed dot product instruction
From CoreDSL to a customized RISC-V core
While CoreDSL is microarchitecture-agnostic, actually implementing and integrating an ISAX is highly dependent on the targeted RISC-V base core. Different microarchitectures influence when operands are available and when results have to be written back.
Our toolflow has two key components: Longnail and SCAIE-V (cf. Figure 1). Longnail is responsible for bridging the gap from the high-level ISAX description, written in CoreDSL, to low-level Verilog code. This step is called high-level synthesis (HLS) and is the key enabler for descriptions that are both concise and portable across different base core microarchitectures. However, just generating the Verilog RTL for the ISAX is only one part of the solution. The ISAX must adhere to some interface to communicate with the base core. For this purpose, our SCAIE-V tooling generates a bespoke core-ISAX interface, custom-tailored for the actual needs of the current ISAX. This not only reduces overheads to the minimum, it also provides Longnail with a “virtual datasheet” of the core, describing, e.g., cycle-constraints on the availability of ISAX operands or results.
SCAIE-V has recently been extended to not just support microcontroller (MCU)-class base cores, but also the far more complex Application-class cores CVA5, in the MANNHEIM-FlexKI project, and CVA6, in the TRISTAN project.
In a nutshell, SCAIE-V supports ISAX-internal state, custom memory accesses and control-flow, and four different execution modes for the ISAX:
- In-pipeline: Longnail ensures that the ISAX matches the base core’s pipeline, and infers stall logic to allow for longer multi-cycle ISAXes.
- Semi-coupled: For long-running ISAXes, SCAIE-V transparently generates stalling logic for MCU-class cores. However, for Application-class cores, SCAIE-V is able to reuse the core’s existing hazard handling logic to prevent stalling.
- Decoupled: As an alternative to the semi-coupled mode, decoupled ISAXes are retired from the processor pipeline before completion, freeing up processor resources. For late register writebacks, SCAIE-V then instantiates its own data hazard handling logic.
- Always: For background tasks that continuously observe and optionally manipulate the pipeline (e.g., hardware loops). Longnail’s always blocks execute independently from fetched instructions, and communicate with software using custom registers provided by dedicated ISAX, which, e.g., set the loop limits for a hardware loop.
For a detailed description of the individual tools, please refer to our publications: SCAIE-V DAC22 paper and Longnail ASPLOS24 paper, respectively.
In addition, SCAIE-V has been released as open-source. It is also proven -in-silicon, having successfully been taped-out as part of a 22nm system-on-chip (cf. SCAIE-V DATE24).
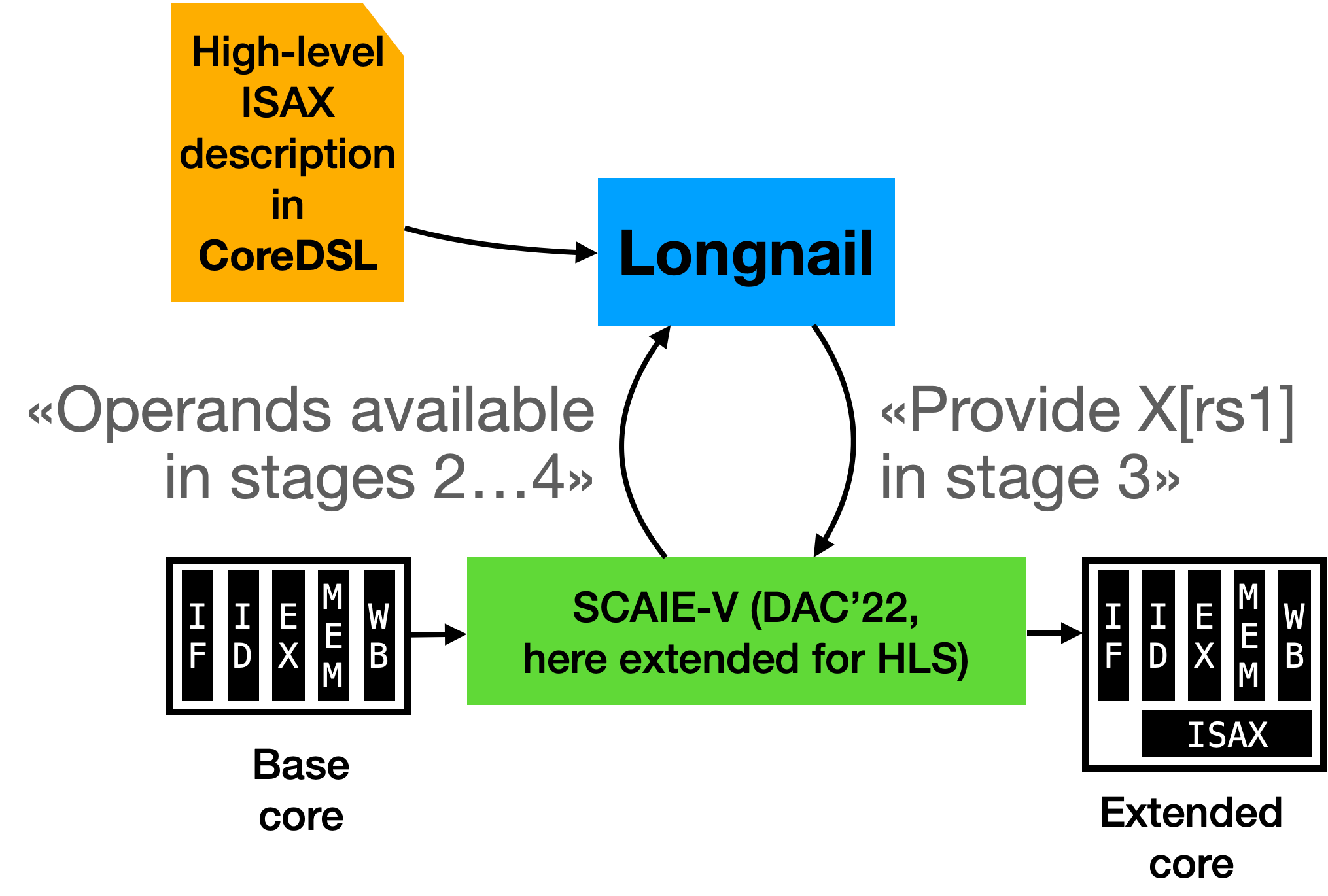
Figure 2: End-to-end flow
For a proper end-to-end flow, we have added automation to invoke our tools with minimal required user interactions. This has been demonstrated at the RISC-V Summit Europe 2024.
Note that our toolflow not just covers the hardware/HLS angle, we also automatically create a customized LLVM-based compiler for using the ISAXes as instrinsics.
On the verification side, we allow the co-execution of C++ based software code using the intrinsics together with an RTL simulation of the ISAXes, without the need to fully simulate the entire base core.
Evaluation
Since our ASPLOS paper, we have added support for CVA5 and CVA6 as Application-class base cores to SCAIE-V, as well as new resource-sharing capabilities to Longnail to reduce the hardware footprint of the interface. We present results obtained on a 22nm ASIC process, using commercial EDA tools for implementation.
ASIC results
While a simple arithmetic instruction (e.g., sbox) will have a low impact across the board, more complex instructions (e.g., dotprod, sparkle) naturally require more hardware area.
Furthermore, the base core microarchitecture matters: For ORCA, the frequency impact of the semi-coupled sqrt instruction is 32%, while the pipeline-decoupled variant slows the core by just 5%, and has a lower area overhead as well. Note that the ISAX hardware and the base core are unchanged, only the integration into the core is different.
The zol hardware loop in general also has a low frequency cost, although it does reduce the timing slack in the core’s “next PC” logic, which reflects on the area utilization of VexRiscv in particular.
On the other hand, the larger CVA5 and CVA6 Application-class cores only see single-digit percentage area and frequency overheads across our entire benchmark set. Being designed to work well with multiple execution units right from the start, these cores see only a minor frequency cost, even for the more complex ISAXes.
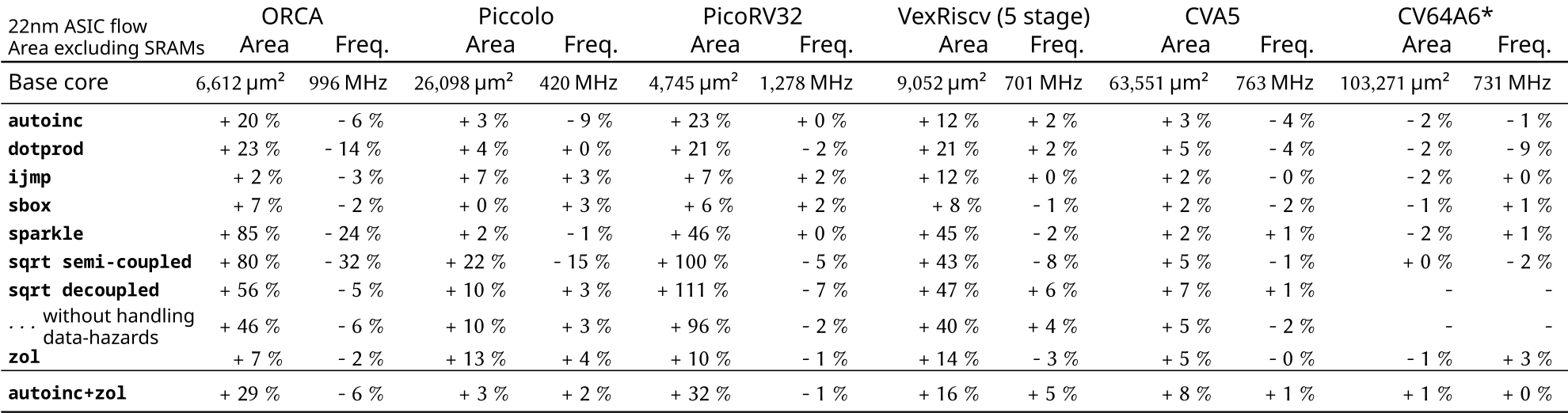
Figure 3: Area and frequency results for a variety of base cores and ISAXes
* preliminary results (CVA6 support is work-in-progress)
Resource Sharing
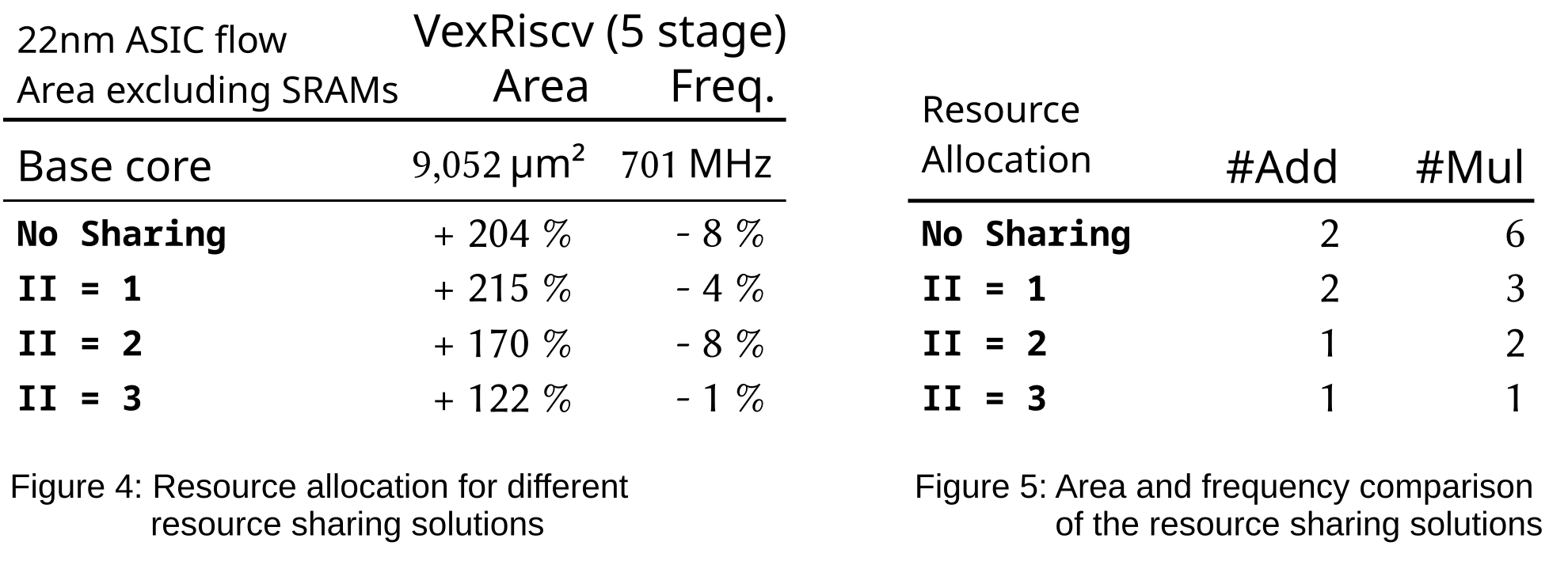
To evaluate the new resource sharing in Longnail, we used a custom vector ISAX. Our vector extension uses its own register file with four three-dimensional vectors and contains instructions for a dot product and an element-wise multiply. Hence, as shown in Figure 4, up to six multipliers and two adders would be required for a fully spatial implementation.
However, Longnail can exploit the microarchitectural details of the base core (here: VexRiscv), as provided by SCAIE-V in a “virtual datasheet”, to perform resource sharing halving the number of multipliers, and still allow executing a vector ISAX each cycle (II=1). Further savings are possible when a reduced issue rate for the ISAX is acceptable, e.g., just every second or third clock cycle (II=2 and 3).
Sample resource-sharing results are shown in Figure 5. Frequency changes remain within the range of EDA tool heuristics noise. Similarly, area savings become notable only at II=2 and 3.
Acknowledgments
Supported by the German Federal Ministry of Education and Research in the projects “Scale4Edge” (grants: 16ME0122K-140, 16ME0465, 16ME0900, 16ME0901) and “MANNHEIM-FlexKI” (grant: 01IS22086A-L). This work has received funding from the Chips Joint Undertaking (CHIPS-JU) TRISTAN project under grant agreement No 101095947. CHIPS JU receives support from the European Union’s Horizon Europe research and innovation programme.
Conclusion
We presented our end-to-end flow from an ISAX formulated in CoreDSL, to synthesis-ready RTL generated by Longnail HLS, and finally to its integration into a base processor using the SCAIE-V tooling. Our flow abstracts the microarchitecture of the target core, reducing the barrier-to-entry for domain-specific additions to the ISA, while also allowing portability across multiple cores supporting advanced ISAX features.
Our findings show that our approach is effective for both MCU- and Application-class cores. Additionally, Longnail’s new configurable resource sharing helps to further optimize the extension’s implementation, matching it to the concrete needs of the application.
Want To Showcase Your Work?
Share your project in the Learn Repository on GitHub! You might find future collaborators or an organization interested in working with you.
Need further instructions? Learn more here!


