


By Zhanheng Yang, Alibaba DAMO Academy
1. Introduction
In the previous article of the XuanTie Optimized Computing Libraries series, we provided a systematic overview of the “XuanTie Optimized Computing Libraries.” We detailed the characteristics and application potential of different optimized libraries and presented performance comparisons across various application scenarios.
Starting with this article, the series will dive deeper into the technical details of the optimization work. This article will introduce the computational optimization process, focusing on vectorization optimization methods.
2. Overview of RVV Optimization
Vectorization is a key computational acceleration method in the RISC-V architecture. It significantly enhances hardware computing efficiency and is widely used in graphics and imaging, audio-video encoding and decoding, data compression, high-performance computing, and machine learning. Its acceleration effect is substantial.
2.1 What is RVV?
RVV (RISC-V Vector Extension) is the vector extension of the RISC-V architecture. It provides the hardware foundation for vectorization optimization. As an open vector processing instruction extension, RVV allows processors to execute parallel data operations, enabling SIMD (Single Instruction, Multiple Data) acceleration. It is designed to enhance the performance of data-intensive computing tasks, making it ideal for highly parallel tasks such as graphics processing, scientific computing, and signal processing.
In addition to its efficient performance in complex computational tasks, the design of RVV also exhibits remarkable scalability and flexibility:
- Scalability: RVV supports variable-length vector registers and variable-width vector operations, allowing flexible adaptation to different hardware implementations. This gives RVV better code reuse compared to vector instruction sets from Arm and x86.
- Flexibility: Vector operations can handle different data types and lengths without significant code changes.
2.2 Basic Concepts of RVV
RVV includes several key components:
1.Vector Registers:
RVV provides a set of vector registers (v0 ~ v31). RVV instructions operate on data stored in these registers. Data is transferred between general-purpose registers and vector registers using vle (load) and vse (store) instructions.
Example:
1 ... 2 vle8.v v0, (a1) // Load data from address in a1 into v0 3 /* 4 RVV computation instructions
5 */ 6 vse8.v v0, (a1) // Store data from v0 to address in a1
2. Vector Register Width (vlen):
vlen determines the maximum parallelism of calculations.
Example: When vlen = 128, the processor can handle 16 8-bit integers or 4 32-bit floating-point values simultaneously.
3. Standard Element Width (sew):
sew defines the width of individual elements during parallel computing.
RVV 1.0 supports sew = 8, 16, 32, 64 bits, covering most integer and floating-point data types in RISC-V.
Example: For uint8 (8-bit unsigned integer) operations, sew = 8.
The number of elements stored in a single register = vlen / sew.
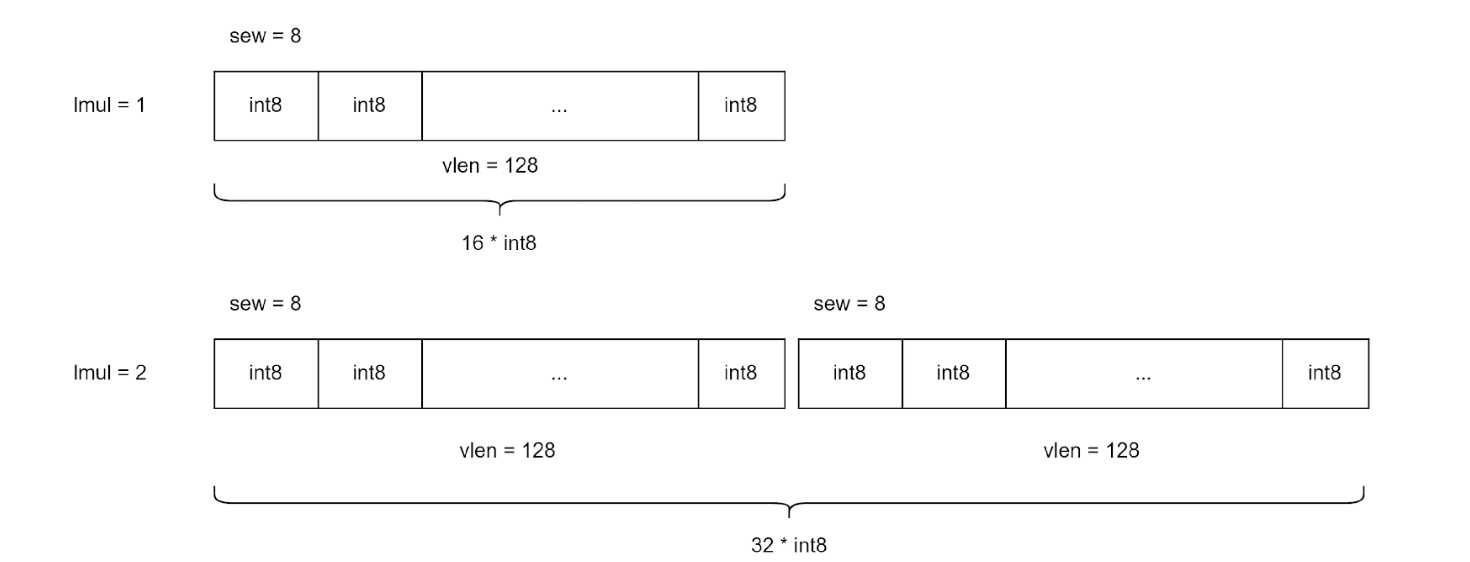
4. Vector Register Grouping (lmul):
Multiple vector registers can be combined into a vector register group. A single instruction can operate on the entire group.
RVV 1.0 supports lmul = 1, 2, 4, 8.
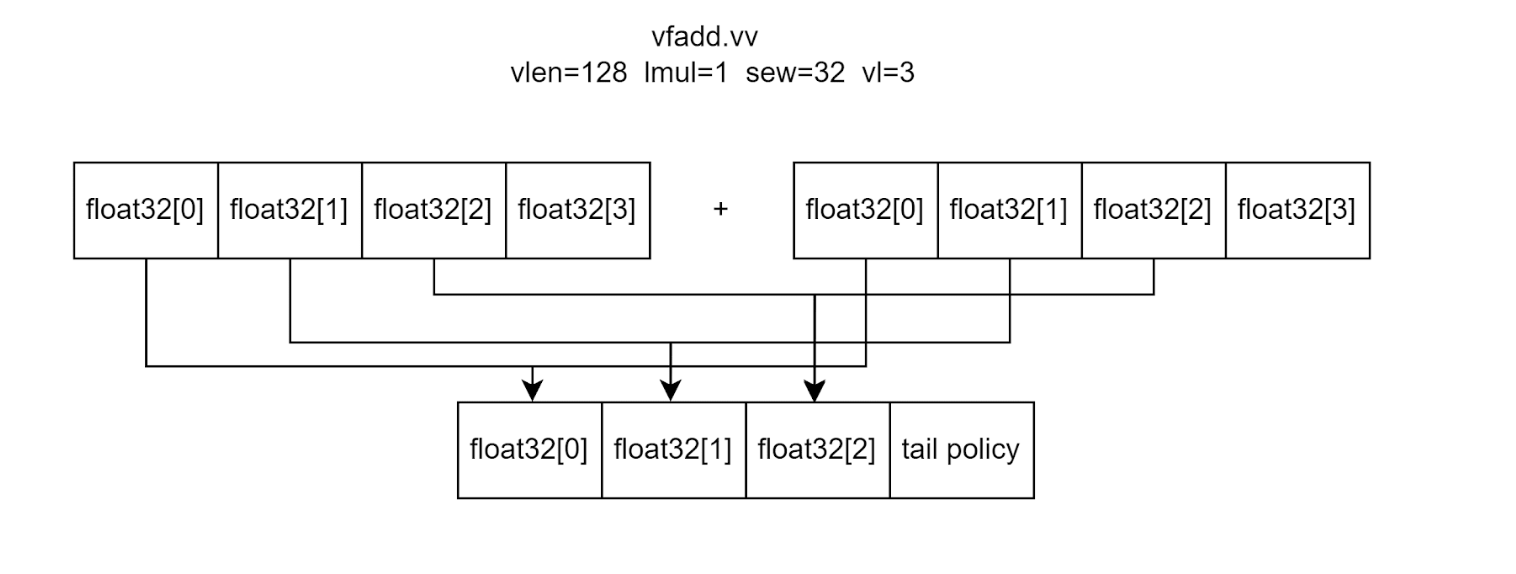
5. Vector Length Register (vl):
The vl register stores the number of elements updated by a vector instruction. During execution, only elements with index < vl are updated.
Example: If vl = 3 for float32 operations and vlen = 128, only the lower 96 bits (3 float32 values) are processed.
3. RVV Optimization Methods
RVV enables parallel computing acceleration for software algorithms, providing a potential multi-fold increase in theoretical performance compared to scalar instructions. The following are three key RVV optimization methods.
3.1 Preconditions for Using RVV Optimization
To accelerate an algorithm or application using RVV, the following conditions must be met:
- Hardware Support:
The hardware platform must support the RISC-V vector extension. - Application Scope:
The target application should be computation-bound. If the application is memory-bound or I/O-bound, the benefits of RVV acceleration may be limited. - Algorithm Structure:
The algorithm must support parallel execution. Elements must be independent, without forward or backward dependencies.
Example: If the result of element b depends on the result of element a, they cannot be processed in parallel.
3.2 Methods for Introducing RVV Optimization
3.2.1 Automatic Vectorization
The RISC-V community and XuanTie toolchain both provide automatic vectorization support. For example, using clang:
- In the RISC-V community, automatic vectorization is enabled by default at O2 and higher. It can be manually enabled at O1 using the -fvectorize option.
- In the XuanTie toolchain, automatic vectorization is enabled using the -xt-enable-vectorization option.
By enabling auto-vectorization, the compiler can identify loops or basic blocks during compilation.It uses data flow and control flow analysis to automatically generate RVV instructions for replacement. This achieves computational acceleration.
Auto-vectorization is simple and convenient, developers do not need to write extra code.
Its optimization strategy is applied globally and covers the entire codebase.
However, it is limited by a relatively simple recognition pattern. Auto-vectorization cannot effectively optimize some complex algorithms at present.
For example, in FFmpeg’s H.264 decoder, automatic vectorization shows limited acceleration for critical modules like qpel compared to manual optimization.
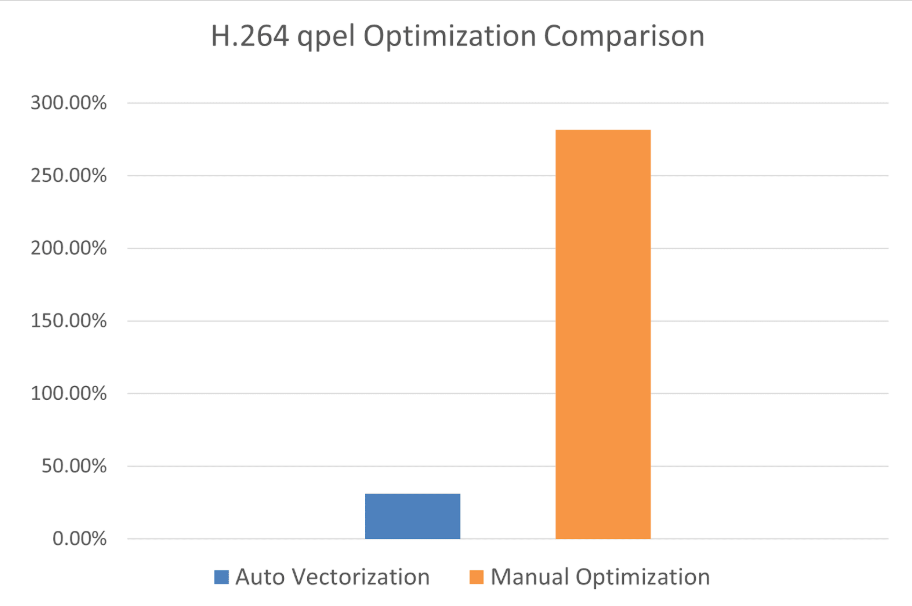
In more extreme cases, if the optimized algorithm differs completely from its naive implementation, auto-vectorization may not optimize at all.
3.2.2 Assembly Optimization
The most direct way to implement RVV acceleration is through hand-written RVV assembly. This is commonly used for core hotspot functions in open-source computing libraries. It provides the most straightforward RVV optimization implementation and can achieve the best optimization effect.
However, assembly optimization has some drawbacks. For example, it demands a higher level of expertise from developers. Developers need to be sufficiently familiar with the acceleration methods and engineering aspects of the optimization algorithm to develop highly efficient optimized code. It also requires certain assembly programming skills. Moreover, manual optimization typically cannot cover the entire project. A common strategy is to optimize the core hotspot functions identified in performance analysis.
Below is an example demonstrating RVV assembly optimization using a simple loop vector addition.
1 //vlen = 128, register a1, a2, a0 to hold the array points, implement a1 + a2 = a0. Register a4 to hold the total array length 2 1: 3 //The main purpose of vsetivli is to set the vector length (vl) while specifying features such as tail policy and mask policy. 4 //sets sew = 8, lmul = 1. The return value t1 is the current loop's vl, when a4 < 16, vl = a4. RVV supports variable-length vector registers in this way. 5 vsetivli t1, a4, e8, m1, ta, ma 6 vle8.v v1, (a1) //Load elements from the given address into the v register 7 vle8.v v2, (a2) 8 addi a1, a1, t1 9 addi a2, a2, t1 10 vadd.vv v0, v1, v2 //Vector Addition 11 vse8.v v0, (a0) //Write the result back to the sum array 12 addi a0, a0, t1 13 addi a4, a4, -t1 14 bnez a4, 1f
3.2.3 Intrinsic Optimization
Intrinsics wrap low-level assembly instructions as C language interfaces.
- Easier for C developers to use.
- Better readability and maintainability.
- More portable across platforms.
Example: Simple vector addition using RVV intrinsics:
1 //vlen = 128 2 while(len > 0) 3 { 4 size_t vl = __riscv_vsetvl_e8m1(len); 5 vuint8m1 va = __riscv_vle8_v_u8m1(a, vl); 6 vuint8m1 vb = __riscv_vle8_v_u8m1(b, vl); 7 vuint8m1 vc = __riscv_vadd_vv_i8m1(va, vb, vl); 8 __riscv_vse8_v_u8m1(c, vc, vl); 9 10 a += vl; 11 b += vl; 12 c += vl; 13 len -= vl; 14 }
4. Results of RVV Optimization
After analyzing performance bottlenecks, the XuanTie team optimized various computing libraries.
Vectorization is one of the key strategies for improving compute-bound algorithms.
Example:
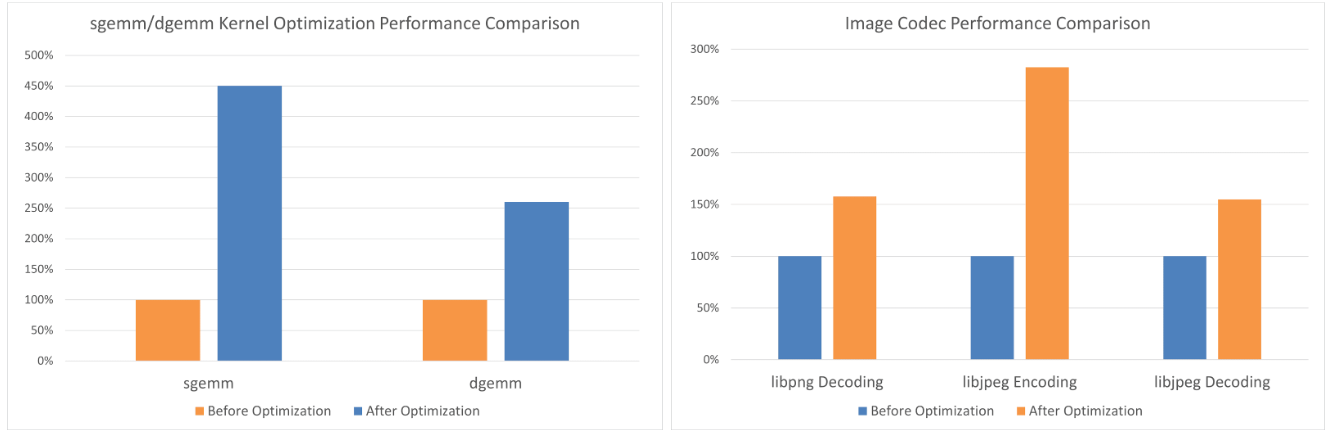
- Eigen: Significant speedup in matrix operations (sgemm/dgemm).
- libjpeg: Encoding and decoding performance increased by over 2× after RVV optimization.
5. Conclusion
Through continuous performance analysis and optimization, the XuanTie team has significantly enhanced the performance of various computing libraries using RVV. These optimizations provide developers with valuable insights and tools for improving software performance on RISC-V platforms.
We will continue introducing more key techniques, implementation methods, and application results of XuanTie optimized computing libraries. Stay tuned!


