


Volker H. Politz, Chief Sales Officer at Semidynamics, explains why the company’s Cervell™ All-in-One IP is so much more than an NPU.
Remember when everyone was talking about ‘big data’? A dominant buzzword in the mid-2010s, it seems to have since been relegated to obscurity. Maybe because we’ve developed more accurate terms (with ‘big data’ seen as an archaic catch-all), or maybe because now, all data is big. Even the tiniest devices doing the simplest jobs churn out gigabytes over time. The conversation has shifted from simply storing and processing big data to how we process it more realistically, more effectively and more intelligently.
As you might expect, the answer in 2025 is ‘we use AI’. In order to do that, though, we need to convert that data into a numerical representation – a vector – that captures the relevant information and makes big data not so big. Once data becomes vectorized, we can work with it far more efficiently. By executing a single operation on multiple data points simultaneously, we massively improve the performance of data processing. Instead of 1024 individual scalar instructions to execute memory loads in a loop (which is slow and inefficient), we can say: “Here’s a vector — load it all at once.” And while this data is being processed efficiently into vectors, we use machine learning (ML) to analyze the data.
In massive data centers, that’s easy. We have the cloud, with virtually limitless compute power. But as we scale down towards edge devices, our options start to decrease. The challenge is how we create something that can handle huge amounts of vectorized data at any level, be it an edge device, laptop, car, server or data center.
Rethinking Heterogeneity
For a while now, the answer has been to embrace heterogeneity – building System on Chips (SoCs) that combine different types of processing cores, like general purpose CPUs, GPUs, vector units and NPUs. By matching each type of workload to the processor best suited for it, systems can run faster and use less power.
Think of it like this: Three people in a room—a thinker, a mathematician, and an artist—passing notes between them. When you’re juggling pre-built IP blocks, a heterogenous SoC provides an effective division of labor. But it also introduces a constant need to move data between those blocks. Each time you transfer data, you lose time, energy, and total system performance.
What if instead of three people in that room you have one polymath who can think, calculate, and create all at once? No data shuffling. No handovers. No bottlenecks. Just a seamless flow of instruction and execution.
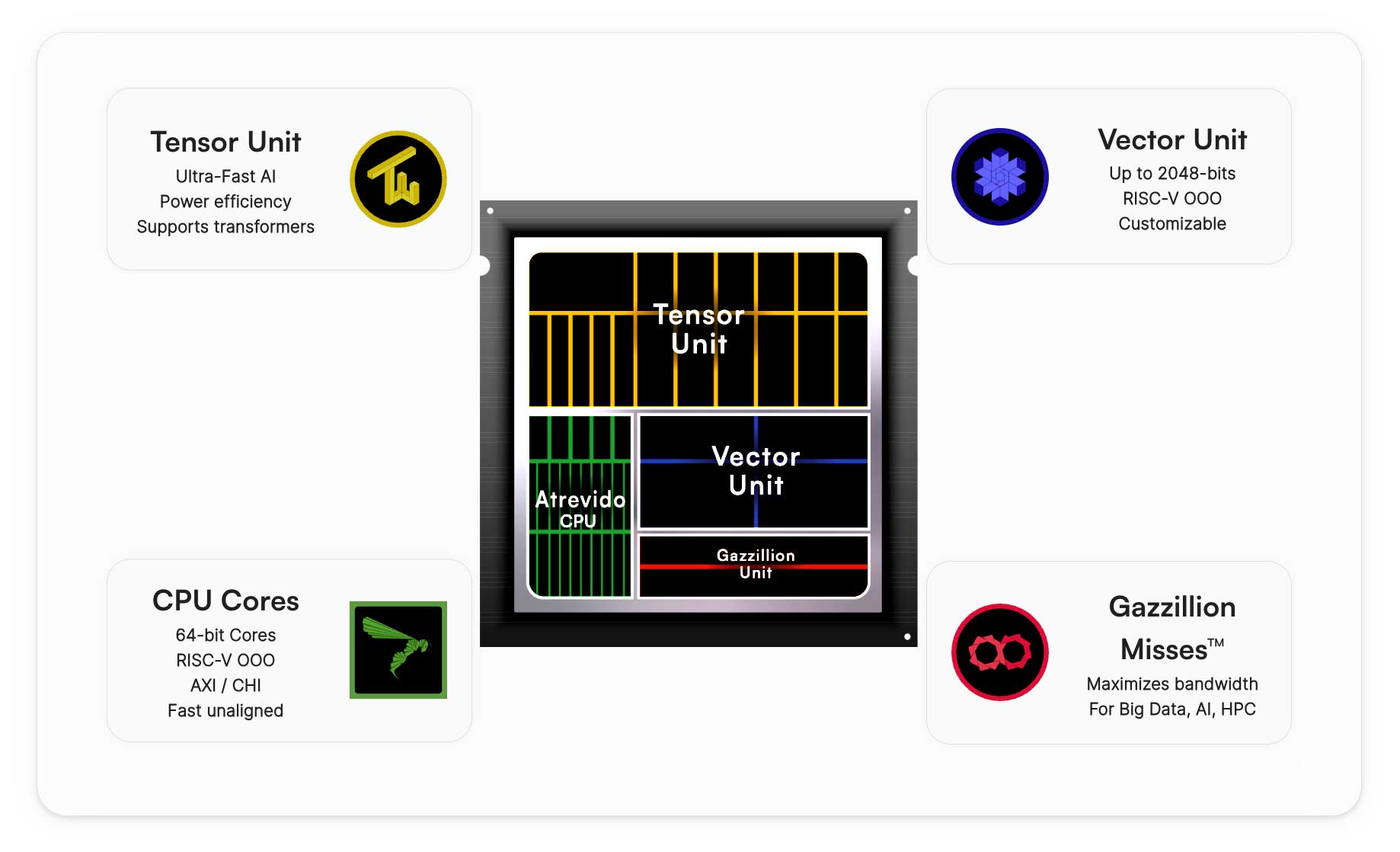
Our NPU is in fact a Tensor unit, Vector unit and CPU, all built on RISC-V
It was this vision that led us to embrace RISC-V’s innate adaptability and build something we call our “All-in-One” (AIO) AI Compute Platform: a unified, deeply integrated core IP solution that marries scalar, vector, and AI compute into a single RISC-V core. It’s designed for flexibility, scalability, and most importantly, for the future.
This month, we announced the first commercial deployment of our AIO platform – the Cervell™ Neural Processing Unit (NPU). Cervell combines AIO’s CPU, vector, and tensor capabilities, unlocking zero-latency AI compute across a range of use cases.
Cervell delivers up to 256 TOPS (Tera Operations Per Second) at 2GHz, scaling from C8 to C64 configurations, allowing designers to tune performance to application needs — from 8 TOPS INT8 at 1GHz in compact edge deployments to 256 TOPS INT4 in high-end AI inference.
It’s a totally new way to think about heterogeneous compute. Let me explain how we got here—and why the all-in-one platform used in Cervell is proving so powerful.
RISC-V Under The Hood
With RISC-V, we’re not locked into legacy architectures. RISC-V’s openness allows for radical rethinking; most legacy vendors are constrained by ISA and toolchain rigidity. We can extend the instruction set to support vector and AI natively—and that’s exactly what we’ve done. Our cores incorporate vector and tensor units and support custom instructions to perform AI workloads directly, without having to shuttle data to a separate NPU.
Another key benefit of using RISC-V as a basis for our IP is its scalability. You can scale up by configuring the IP itself—adjusting the balance between scalar, vector, and AI capabilities. Or you can scale out, deploying multiple instances in a multicore configuration. It’s a RISC-V processor, so everything works as you’d expect with standard Linux tools, workloads, and schedulers.
We support customers building everything from powerful edge AI devices to large data center accelerators. The flexibility of our architecture means we’re not locked into one form factor or one performance envelope.
Developer-Friendly from Day One
Of course, the best hardware is only as good as its software stack. That’s why we’ve made developer experience a priority. Our Aliado SDK is now publicly available on our website. It includes:
- A compiler toolchain based on the RISC-V community standard, but optimized for our IP
- A comprehensive library of vector and mathematical functions
- A full ONNX runtime environment for AI inference
The AI runtime includes ready-to-use execution providers. Developers can bring in their ONNX models, import them, and run them directly—no custom ML compiler needed. We also support other front ends via LLVM and provide standard simulators like QEMU and Spike to help teams get up and running fast.
The Gazillion Misses™ Approach
There’s another string to Cervell’s bow that makes AIO a standout solution, especially when it’s used for high-bandwidth, memory-intensive applications such as AI inference, key-value stores, and sparse data processing. Traditional cores waste 100s of clock cycles waiting for data due to cache misses. A standard L2 cache might hold 1–2 MB, but a single 4K image is around 24 MB. If your CPU is constantly waiting for data to be fetched from DRAM, it doesn’t matter how powerful it is—it’s stalled.
That’s why we built our “Gazillion Misses™” memory management subsystem. It allows our IP to sustain a very high number of cache misses without halting execution. Data is streamed in the background, ensuring continuous data flow. That means no idle cores, and no wasted cycles. Whether you’re processing camera images or running inference on large language models (LLMs), our Atrevido and Avispado cores keep working – processing up to 64 or 128 misses respectively.
Real-World Use Cases
So where does this really shine? Anywhere AI needs to be deployed rapidly and efficiently.
Take LLMs. When DeepSeek open-sourced its model, it took us just three days to get it running on our FPGA platform. That kind of agility—being able to evaluate, optimise, and deploy new models quickly—is a game-changer in a fast-moving space like AI.
Another sweet spot is big data movement in the data center. With large vector units, our IP can move massive amounts of data with fewer cores and lower power. We’re seeing real traction from customers who need to do fast, flexible processing without over-provisioning hardware. Our IP might not become the main CPU in a server, but it’ll drive accelerator cards doing AI, storage compression, or custom workloads. RISC-V gives customers freedom to innovate and differentiate.
Then there’s the embedded space. Applications like smart security cameras, AI gateways or automotive zone controllers demand powerful local processing at the edge. We’re already seeing strong interest from automotive OEMs who need future-proof, open platforms to avoid vendor lock-in—and who are increasingly concerned about ensuring longevity and upgradeability.
Future-Proof by Design
One of the biggest pain points with traditional NPUs is what I call the “tape-out trap.” You build your NPU, tape it out, and six months later a new algorithm comes along—and your silicon can’t run it. That’s not sustainable.
Our All-in-One IP doesn’t suffer from that problem. It’s based on a RISC-V CPU, with a programmable instruction set. If there’s a new algorithm that can be described in logic or math, you can run it. You can write the code yourself or use our libraries, but you’re never stuck with a fixed-function block that’s obsolete before it even ships.
This future-proofing is also what’s making us attractive to a new kind of customer: companies who traditionally only considered dedicated NPUs. We’re now offering them configurable IP that delivers the performance they need today, and the flexibility they’ll need tomorrow.
Looking forward, we’re doubling down on this approach. We’re already working with customers to deliver configured AI IP blocks tailored to specific performance goals. In the near future, we’ll offer these as standalone NPU-style cores—except they’ll be built on our All-in-One architecture, giving developers a CPU-like experience with AI-class performance.
To help customers evaluate our IP, we’re even making FPGA benchmarking platforms available. You can log in, run your own code, and see the results for yourself.
At Semidynamics, we believe the best IP doesn’t force customers to choose between heterogenous flexibility and performance. With Cervell™ and our All-in-One RISC-V architecture, you get both—and a path to whatever the future of AI demands.
Discover Semidynamics’ range of groundbreaking RISC-V IP now.


