

Author: Prof. Jun Han, Fudan University
T-Head made the Xuantie RISC-V series processors open-source and made a series of tools and system software available at the 2021 Apsara Conference. This was the first full-stack open-source of the series processors and basic software worldwide. T-Head strives to promote the maturity of RISC-V architecture and accelerate the fusion and development between RISC-V soft and hardware technologies.
We have received tremendous interests and positive feedback regarding the Open Xuantie project from the community during the past year. On the recent China National Computer Congress(CNCC) 2022, Pro. Jun Han from Fudan University demonstrated their latest achievement on DSA Agile development on Open Xuantie RISC-V processor. This is the first significant DSA realization on the Open Xuantie C910 core.
Due to its explosive growth and edge application scenarios, IoT has caused significant differentiation and fragmentation in the design requirements. The existing design requires much longer time in development, hence lacking rapid customization in domain-specific processors. Therefore, it is essential to explore an agile domain-specific processor design to cope with the demand of massive fragmentation design requirements of domain-specific XPUs.
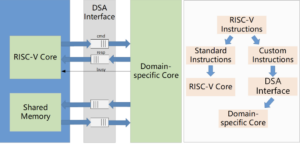
Fig. 1. DSA Interface and Custom Instruction Extension
Fortunately, the open-source instruction set RISC-V is designed for modularity and extensibility. This design also enables DSAs agilely by custom instruction extensions. The Hardware/Software co-design strategy allows the domain-specific tasks to be accelerated through the cooperation of the general-purpose and domain-specific core. The general purpose is designed to complete the normal tasks but offloading heavy computations, represented by the custom instructions, to the domain-specific core. This DSA design paradigm can improve the flexibility and programmability of DSA, provided by the Turing-complete general-purpose core while gaining performance advantages through the domain-specific core.
To further achieve agile development, we designed domain-specific core conveniently to be coupled to the RISC-V core with little change to the internal pipeline. We implemented an efficient DSA interface to bridge the communication and cooperation between the general-purpose and domain-specific cores, as shown in Fig. 1.
DSA Interface Design based on Open Xuantie C910
We have developed a demo of a DSA interface called Xuantie DSA Interface. It is designed based on the Open Xuantie C910 processor. The interface allows tight coupling between the domain-specific core and the Xuantie C910 core, efficiently supporting HW/SW co-design.
The Xuantie DSA Interface provides three sets of platforms for development optimization: the command, the L1 Cache access, and the L2 Cache access interfaces.
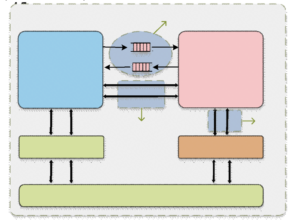
Fig. 2. The Xuantie DSA Interface
The command interface provides a command request and response channel. The domain-specific core can directly access register resources and instruction streams through this interface. The interaction between general purpose and domain specific cores can reach for low latency through the tight coupling. Moreover, full 32-bit instructions can be freely decoded by the latter for more information.
The L1 Cache access interface provides a pipelined channel for the access. The domain-specific core will provide information, such as virtual addresses, stored data, and memory access type to access the L1-Cache. In addition, the memory consistency issue will be guaranteed by the Load-Store Unit (LSU) of the Xuantie C910 core.
The L2 Cache access interface allows for a large-bandwidth memory access channel. The read and write channels are separated in order to be processed separately The domain-specific core can efficiently access large contiguous data by providing only address, data, byte count, etc.
DSA Design Case Using Xuantie DSA Interface
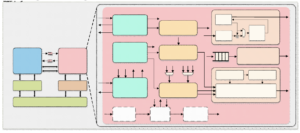
Fig. 3. The architecture of the proposed domain-specific processor
Based on the proposed Xuantie DSA Interface, we design a domain-specific processor, as shown in Fig. 3.
The DSA design process starts with the profiling of target algorithms. From the profiling report, we then extract the performance bottleneck operations. In order to better exploit the data-level parallelism inherent in the algorithms, we reshape scalar-based kernel operations into matrix-based ones via 2-D data structure abstraction. Based on this design, we design a set of custom matrix instructions. We also implement a Crypto-core to perform these custom instructions coupling to the Xuantie C910 Core through the Xuantie DSA Interface.
The command interface is connected to the local Decoder unit in the Crypto-core. This part is responsible to accept and decode the custom instructions as well as return the corresponding response through the command interface. The memory access interface is driven by the Load/Store Control Unit to initial memory access requests and receive responses; the memory access address length is determined by the current custom instruction and CSR settings. To improve the memory access efficiency in this application scenario, we try both the L1 Cache and L2 Cache access interfaces; we find that the Crypto-core is more suitable to connect to the shared memory with the RISC-V Core through the L2 Cache access interface, as the polynomial, the main operation object, is stored in the array and distributed continuously in the memory.
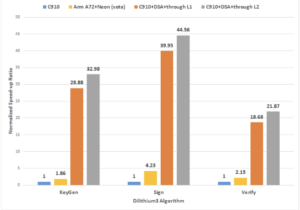
Fig. 4. Implementation and comparison results for digital signature scheme, Dilithium-Ⅲ
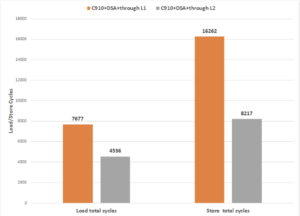
Fig. 5. Clock cycle count consumed by memory access in the Sign process of Dilithium-Ⅲ
We present the cycle count results of implementing the Dilithium digital signature scheme on the proposed architecture in Fig. 4. Compared to the software baseline implementation running in scalar Xuantie C910 core, we propose that the DSA design achieves up to 44.56× improvement in performance. Compared to the state-of-the-art implementation in Arm A72 accelerated by Arm Neon SIMD extension, up to 17.73× acceleration is achieved by the proposed DSA. We additionally present the clock cycle count consumed by memory access in the Sign process of Dilithium-Ⅲ in Fig. 5. It can be seen that the L2 memory access interface is 1.69× and 1.98× faster than the L1 interface, respectively, performing memory Load and Store on large continuous data; we obtain about 10% overall performance gain by using L2 Cache access interface instead of the L1 interface.
Conclusion
We have successfully developed a DSA interface on Open Xuantie C910, featuring a command interface with processor and two memory interfaces with L1 and L2 Cache. This interface will be open source and merged to the Open Xuantie C910 project. We are confident that this agile development method presented could be instructive for future domain-specific architecture design based on Open Xuantie C910 processor.

